移动部分的题的实现
This commit is contained in:
parent
375ffd2a40
commit
6f8ed33ed5
|
|
@ -126,29 +126,48 @@ mod q0605;
|
|||
mod q0617;
|
||||
mod q0628;
|
||||
mod q0633;
|
||||
mod q0643;
|
||||
mod q0674;
|
||||
mod q0684;
|
||||
mod q0690;
|
||||
mod q0693;
|
||||
mod q0695;
|
||||
mod q0704;
|
||||
mod q0721;
|
||||
mod q0724;
|
||||
mod q0733;
|
||||
mod q0740;
|
||||
mod q0746;
|
||||
mod q0778;
|
||||
mod q0781;
|
||||
mod q0783;
|
||||
mod q0803;
|
||||
mod q0830;
|
||||
mod q0839;
|
||||
mod q0872;
|
||||
mod q0876;
|
||||
mod q0888;
|
||||
mod q0897;
|
||||
mod q0912;
|
||||
mod q0918;
|
||||
mod q0938;
|
||||
mod q0947;
|
||||
mod q0959;
|
||||
mod q0965;
|
||||
mod q0977;
|
||||
mod q0989;
|
||||
mod q0995;
|
||||
mod q1006;
|
||||
mod q1011;
|
||||
mod q1018;
|
||||
mod q1022;
|
||||
mod q1025;
|
||||
mod q1108;
|
||||
mod q1128;
|
||||
mod q1137;
|
||||
mod q1143;
|
||||
mod q1190;
|
||||
mod q1202;
|
||||
mod q1218;
|
||||
mod q1269;
|
||||
mod q1310;
|
||||
|
|
@ -162,4 +181,3 @@ mod q1734;
|
|||
mod q1791;
|
||||
mod q1984;
|
||||
mod q2006;
|
||||
mod q0643;
|
||||
|
|
|
|||
|
|
@ -0,0 +1,50 @@
|
|||
use crate::Solution;
|
||||
|
||||
impl Solution {
|
||||
/// [674.最长连续递增序列](https://leetcode-cn.com/problems/longest-continuous-increasing-subsequence/)
|
||||
///
|
||||
/// 2022-02-21 12:23:20
|
||||
///
|
||||
/// 给定一个未经排序的整数数组,找到最长且 **连续递增的子序列**,并返回该序列的长度。
|
||||
///
|
||||
/// **连续递增的子序列** 可以由两个下标 `l` 和 `r`(`l < r`)确定,如果对于每个 `l <= i < r`,都有 `nums[i] < nums[i + 1]` ,那么子序列 `[nums[l], nums[l + 1], ..., nums[r - 1], nums[r]]` 就是连续递增子序列。
|
||||
///
|
||||
/// + **示例 1:**
|
||||
/// + **输入:** nums = \[1,3,5,4,7\]
|
||||
/// + **输出:** 3
|
||||
/// + **解释:**
|
||||
/// - 最长连续递增序列是 \[1,3,5\], 长度为3。
|
||||
/// - 尽管 \[1,3,5,7\] 也是升序的子序列, 但它不是连续的,因为 5 和 7 在原数组里被 4 隔开。
|
||||
/// + **示例 2:**
|
||||
/// + **输入:** nums = \[2,2,2,2,2\]
|
||||
/// + **输出:** 1
|
||||
/// + **解释:** 最长连续递增序列是 \[2\], 长度为1。
|
||||
/// + **提示:**
|
||||
/// * `1 <= nums.length <= 104`
|
||||
/// * `-109 <= nums[i] <= 109`
|
||||
/// + Related Topics
|
||||
/// * 数组
|
||||
/// * 👍 241
|
||||
/// * 👎 0
|
||||
pub fn find_length_of_lcis(nums: Vec<i32>) -> i32 {
|
||||
let mut ans = 0;
|
||||
let mut start = 0;
|
||||
for i in 0..nums.len() {
|
||||
if i > 0 && nums[i] <= nums[i - 1] {
|
||||
start = i;
|
||||
}
|
||||
ans = ans.max(i - start + 1);
|
||||
}
|
||||
ans as i32
|
||||
}
|
||||
}
|
||||
|
||||
#[cfg(test)]
|
||||
mod test {
|
||||
use crate::Solution;
|
||||
|
||||
#[test]
|
||||
fn test_q0674() {
|
||||
assert_eq!(Solution::find_length_of_lcis(vec![1, 3, 5, 4, 7]), 3);
|
||||
}
|
||||
}
|
||||
|
|
@ -0,0 +1,75 @@
|
|||
use crate::Solution;
|
||||
|
||||
impl Solution {
|
||||
/// [684.冗余连接](https://leetcode-cn.com/problems/redundant-connection/)
|
||||
///
|
||||
/// 2022-02-21 16:49:22
|
||||
///
|
||||
/// 树可以看成是一个连通且 **无环** 的 **无向** 图。
|
||||
///
|
||||
/// 给定往一棵 `n` 个节点 (节点值 `1~n`) 的树中添加一条边后的图。添加的边的两个顶点包含在 `1` 到 `n` 中间,且这条附加的边不属于树中已存在的边。图的信息记录于长度为 `n` 的二维数组 `edges` ,`edges[i] = [ai, bi]` 表示图中在 `ai` 和 `bi` 之间存在一条边。
|
||||
///
|
||||
/// 请找出一条可以删去的边,删除后可使得剩余部分是一个有着 `n` 个节点的树。如果有多个答案,则返回数组 `edges` 中最后出现的边。
|
||||
///
|
||||
/// + **示例 1:**
|
||||
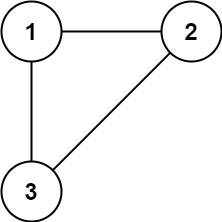
/// + 
|
||||
/// + **输入:** edges = \[\[1,2\], \[1,3\], \[2,3\]\]
|
||||
/// + **输出:** \[2,3\]
|
||||
/// + **示例 2:**
|
||||
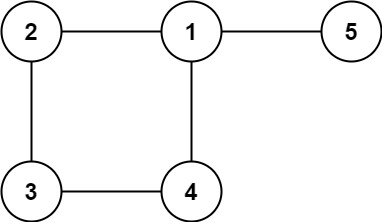
/// + 
|
||||
/// + **输入:** edges = \[\[1,2\], \[2,3\], \[3,4\], \[1,4\], \[1,5\]\]
|
||||
/// + **输出:** \[1,4\]
|
||||
/// + **提示:**
|
||||
/// * `n == edges.length`
|
||||
/// * `3 <= n <= 1000`
|
||||
/// * `edges[i].length == 2`
|
||||
/// * `1 <= ai < bi <= edges.length`
|
||||
/// * `ai != bi`
|
||||
/// * `edges` 中无重复元素
|
||||
/// * 给定的图是连通的
|
||||
/// + Related Topics
|
||||
/// * 深度优先搜索
|
||||
/// * 广度优先搜索
|
||||
/// * 并查集
|
||||
/// * 图
|
||||
/// * 👍 431
|
||||
/// * 👎 0
|
||||
pub fn find_redundant_connection(edges: Vec<Vec<i32>>) -> Vec<i32> {
|
||||
fn find(parent: &mut Vec<usize>, index: usize) -> usize {
|
||||
if parent[index] != index {
|
||||
parent[index] = find(parent, parent[index]);
|
||||
}
|
||||
parent[index]
|
||||
}
|
||||
fn union(parent: &mut Vec<usize>, index1: usize, index2: usize) {
|
||||
let idx1 = find(parent, index1);
|
||||
let idx2 = find(parent, index2);
|
||||
parent[idx1] = idx2;
|
||||
}
|
||||
|
||||
let nodes_count = edges.len();
|
||||
let mut parent = (0..nodes_count + 1).collect::<Vec<usize>>();
|
||||
for edge in edges {
|
||||
let (node1, node2) = (edge[0] as usize, edge[1] as usize);
|
||||
if find(&mut parent, node1) != find(&mut parent, node2) {
|
||||
union(&mut parent, node1, node2);
|
||||
} else {
|
||||
return edge;
|
||||
}
|
||||
}
|
||||
Vec::<i32>::new()
|
||||
}
|
||||
}
|
||||
|
||||
#[cfg(test)]
|
||||
mod test {
|
||||
use crate::Solution;
|
||||
|
||||
#[test]
|
||||
fn test_q0684() {
|
||||
let edges = vec![vec![1, 2], vec![2, 3], vec![3, 4], vec![1, 4], vec![1, 5]];
|
||||
let redundant_connection = Solution::find_redundant_connection(edges);
|
||||
//println!("{:?}", redundant_connection);
|
||||
assert_eq!(redundant_connection, vec![1, 4]);
|
||||
}
|
||||
}
|
||||
|
|
@ -0,0 +1,42 @@
|
|||
use crate::Solution;
|
||||
|
||||
impl Solution {
|
||||
/// [693.交替位二进制数](https://leetcode-cn.com/problems/binary-number-with-alternating-bits/)
|
||||
///
|
||||
/// 2022-02-21 16:53:10
|
||||
///
|
||||
/// 给定一个正整数,检查它的二进制表示是否总是 0、1 交替出现:换句话说,就是二进制表示中相邻两位的数字永不相同。
|
||||
///
|
||||
/// + **示例 1:**
|
||||
/// + **输入:** n = 5
|
||||
/// + **输出:** true
|
||||
/// + **解释:** 5 的二进制表示是:101
|
||||
/// + **示例 2:**
|
||||
/// + **输入:** n = 7
|
||||
/// + **输出:** false
|
||||
/// + **解释:** 7 的二进制表示是:111.
|
||||
/// + **示例 3:**
|
||||
/// + **输入:** n = 11
|
||||
/// + **输出:** false
|
||||
/// + **解释:** 11 的二进制表示是:1011.
|
||||
/// + **提示:**
|
||||
/// * `1 <= n <= 231 - 1`
|
||||
/// + Related Topics
|
||||
/// * 位运算
|
||||
/// * 👍 113
|
||||
/// * 👎 0
|
||||
pub fn has_alternating_bits(n: i32) -> bool {
|
||||
let n = (n ^ (n >> 1));
|
||||
(n as i64 & (n as i64 + 1)) == 0
|
||||
}
|
||||
}
|
||||
|
||||
#[cfg(test)]
|
||||
mod test {
|
||||
use crate::Solution;
|
||||
|
||||
#[test]
|
||||
fn test_q0693() {
|
||||
assert_eq!(Solution::has_alternating_bits(11), false);
|
||||
}
|
||||
}
|
||||
|
|
@ -0,0 +1,119 @@
|
|||
use crate::Solution;
|
||||
|
||||
impl Solution {
|
||||
/// [721.账户合并](https://leetcode-cn.com/problems/accounts-merge/)
|
||||
///
|
||||
/// 2022-02-21 16:56:57
|
||||
///
|
||||
/// 给定一个列表 `accounts`,每个元素 `accounts[i]` 是一个字符串列表,其中第一个元素 `accounts[i][0]` 是 _名称 (name)_,其余元素是 _**emails**_ 表示该账户的邮箱地址。
|
||||
///
|
||||
/// 现在,我们想合并这些账户。如果两个账户都有一些共同的邮箱地址,则两个账户必定属于同一个人。请注意,即使两个账户具有相同的名称,它们也可能属于不同的人,因为人们可能具有相同的名称。一个人最初可以拥有任意数量的账户,但其所有账户都具有相同的名称。
|
||||
///
|
||||
/// 合并账户后,按以下格式返回账户:每个账户的第一个元素是名称,其余元素是 **按字符 ASCII 顺序排列** 的邮箱地址。账户本身可以以 **任意顺序** 返回。
|
||||
///
|
||||
/// + **示例 1:**
|
||||
/// + **输入:** accounts = \[\["John", "johnsmith@mail.com", "john00@mail.com"\], \["John", "johnnybravo@mail.com"\], \["John", "johnsmith@mail.com", "john\_newyork@mail.com"\], \["Mary", "mary@mail.com"\]\]
|
||||
/// + **输出:** \[\["John", 'john00@mail.com', 'john\_newyork@mail.com', 'johnsmith@mail.com'\], \["John", "johnnybravo@mail.com"\], \["Mary", "mary@mail.com"\]\]
|
||||
/// + **解释:**
|
||||
/// - 第一个和第三个 John 是同一个人,因为他们有共同的邮箱地址 "johnsmith@mail.com"。
|
||||
/// - 第二个 John 和 Mary 是不同的人,因为他们的邮箱地址没有被其他帐户使用。
|
||||
/// - 可以以任何顺序返回这些列表,例如答案 \[\['Mary','mary@mail.com'\],\['John','johnnybravo@mail.com'\],
|
||||
/// - \['John','john00@mail.com','john\_newyork@mail.com','johnsmith@mail.com'\]\] 也是正确的。
|
||||
/// + **示例 2:**
|
||||
/// + **输入:** accounts = \[\["Gabe","Gabe0@m.co","Gabe3@m.co","Gabe1@m.co"\],\["Kevin","Kevin3@m.co","Kevin5@m.co","Kevin0@m.co"\],\["Ethan","Ethan5@m.co","Ethan4@m.co","Ethan0@m.co"\],\["Hanzo","Hanzo3@m.co","Hanzo1@m.co","Hanzo0@m.co"\],\["Fern","Fern5@m.co","Fern1@m.co","Fern0@m.co"\]\]
|
||||
/// + **输出:** \[\["Ethan","Ethan0@m.co","Ethan4@m.co","Ethan5@m.co"\],\["Gabe","Gabe0@m.co","Gabe1@m.co","Gabe3@m.co"\],\["Hanzo","Hanzo0@m.co","Hanzo1@m.co","Hanzo3@m.co"\],\["Kevin","Kevin0@m.co","Kevin3@m.co","Kevin5@m.co"\],\["Fern","Fern0@m.co","Fern1@m.co","Fern5@m.co"\]\]
|
||||
/// + **提示:**
|
||||
/// * `1 <= accounts.length <= 1000`
|
||||
/// * `2 <= accounts[i].length <= 10`
|
||||
/// * `1 <= accounts[i][j].length <= 30`
|
||||
/// * `accounts[i][0]` 由英文字母组成
|
||||
/// * `accounts[i][j] (for j > 0)` 是有效的邮箱地址
|
||||
/// + Related Topics
|
||||
/// * 深度优先搜索
|
||||
/// * 广度优先搜索
|
||||
/// * 并查集
|
||||
/// * 数组
|
||||
/// * 字符串
|
||||
/// * 👍 344
|
||||
/// * 👎 0
|
||||
pub fn accounts_merge(accounts: Vec<Vec<String>>) -> Vec<Vec<String>> {
|
||||
fn find(parent: &mut Vec<usize>, index: usize) -> usize {
|
||||
if parent[index] != index {
|
||||
parent[index] = find(parent, parent[index]);
|
||||
}
|
||||
parent[index]
|
||||
}
|
||||
fn union(parent: &mut Vec<usize>, index1: usize, index2: usize) {
|
||||
let idx1 = find(parent, index1);
|
||||
let idx2 = find(parent, index2);
|
||||
parent[idx2] = idx1;
|
||||
}
|
||||
use std::collections::HashMap;
|
||||
let mut email_to_idx = HashMap::<String, usize>::new();
|
||||
let mut email_to_name = HashMap::<String, String>::new();
|
||||
let mut emails_count = 0usize;
|
||||
for account in &accounts {
|
||||
let name = &account[0];
|
||||
for i in 1..account.len() {
|
||||
let email = &account[i];
|
||||
if !email_to_idx.contains_key(email) {
|
||||
email_to_idx.insert(email.clone(), emails_count);
|
||||
email_to_name.insert(email.clone(), name.clone());
|
||||
emails_count += 1;
|
||||
}
|
||||
}
|
||||
}
|
||||
let mut parent = (0..emails_count).collect::<Vec<usize>>();
|
||||
for account in &accounts {
|
||||
let first_email = &account[1];
|
||||
let first_idx = email_to_idx[first_email];
|
||||
for i in 2..account.len() {
|
||||
let next_email = &account[i];
|
||||
let next_idx = email_to_idx[next_email];
|
||||
union(&mut parent, first_idx, next_idx);
|
||||
}
|
||||
}
|
||||
let mut idx_to_emails = HashMap::<usize, Vec<String>>::new();
|
||||
for email in email_to_idx.keys() {
|
||||
let idx = find(&mut parent, email_to_idx[email]);
|
||||
if !idx_to_emails.contains_key(&idx) {
|
||||
idx_to_emails.insert(idx, Vec::<String>::new());
|
||||
}
|
||||
idx_to_emails.get_mut(&idx).unwrap().push(email.clone());
|
||||
}
|
||||
let mut merged = Vec::<Vec<String>>::new();
|
||||
for emails in idx_to_emails.values_mut() {
|
||||
emails.sort();
|
||||
let name = &email_to_name[&emails[0]];
|
||||
let mut account = Vec::<String>::with_capacity(1usize + emails.len());
|
||||
account.push(name.clone());
|
||||
account.extend(emails.clone());
|
||||
merged.push(account);
|
||||
}
|
||||
merged
|
||||
}
|
||||
}
|
||||
|
||||
#[cfg(test)]
|
||||
mod test {
|
||||
use crate::Solution;
|
||||
|
||||
#[test]
|
||||
fn test_q0721() {
|
||||
let accounts = vec![
|
||||
vec!["John".to_string(), "johnsmith@mail.com".to_string(), "john00@mail.com".to_string()],
|
||||
vec!["John".to_string(), "johnnybravo@mail.com".to_string()],
|
||||
vec!["John".to_string(), "johnsmith@mail.com".to_string(), "john_newyork@mail.com".to_string()],
|
||||
vec!["Mary".to_string(), "mary@mail.com".to_string()]];
|
||||
let ans = vec![
|
||||
vec!["Mary".to_string(), "mary@mail.com".to_string()],
|
||||
vec!["John".to_string(), "john00@mail.com".to_string(), "john_newyork@mail.com".to_string(), "johnsmith@mail.com".to_string()],
|
||||
vec!["John".to_string(), "johnnybravo@mail.com".to_string()]];
|
||||
let merged = Solution::accounts_merge(accounts);
|
||||
for a in &merged {
|
||||
if !ans.contains(a) {
|
||||
panic!()
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
|
|
@ -0,0 +1,66 @@
|
|||
use crate::Solution;
|
||||
|
||||
impl Solution {
|
||||
/// [724.寻找数组的中心下标](https://leetcode-cn.com/problems/find-pivot-index/)
|
||||
///
|
||||
/// 2022-02-21 17:09:50
|
||||
///
|
||||
/// 给你一个整数数组 `nums` ,请计算数组的 **中心下标** 。
|
||||
///
|
||||
/// 数组 **中心下标** 是数组的一个下标,其左侧所有元素相加的和等于右侧所有元素相加的和。
|
||||
///
|
||||
/// 如果中心下标位于数组最左端,那么左侧数之和视为 `0` ,因为在下标的左侧不存在元素。这一点对于中心下标位于数组最右端同样适用。
|
||||
///
|
||||
/// 如果数组有多个中心下标,应该返回 **最靠近左边** 的那一个。如果数组不存在中心下标,返回 `-1` 。
|
||||
///
|
||||
/// + **示例 1:**
|
||||
/// + **输入:** nums = \[1, 7, 3, 6, 5, 6\]
|
||||
/// + **输出:** 3
|
||||
/// + **解释:**
|
||||
/// - 中心下标是 3 。
|
||||
/// - 左侧数之和 sum = nums\[0\] + nums\[1\] + nums\[2\] = 1 + 7 + 3 = 11 ,
|
||||
/// - 右侧数之和 sum = nums\[4\] + nums\[5\] = 5 + 6 = 11 ,二者相等。
|
||||
/// + **示例 2:**
|
||||
/// + **输入:** nums = \[1, 2, 3\]
|
||||
/// + **输出:** \-1
|
||||
/// + **解释:**
|
||||
/// - 数组中不存在满足此条件的中心下标。
|
||||
/// + **示例 3:**
|
||||
/// + **输入:** nums = \[2, 1, -1\]
|
||||
/// + **输出:** 0
|
||||
/// + **解释:**
|
||||
/// - 中心下标是 0 。
|
||||
/// - 左侧数之和 sum = 0 ,(下标 0 左侧不存在元素),
|
||||
/// - 右侧数之和 sum = nums\[1\] + nums\[2\] = 1 + -1 = 0 。
|
||||
/// + **提示:**
|
||||
/// * `1 <= nums.length <= 104`
|
||||
/// * `-1000 <= nums[i] <= 1000`
|
||||
/// + **注意:** 本题与主站 1991 题相同:[https://leetcode-cn.com/problems/find-the-middle-index-in-array/](https://leetcode-cn.com/problems/find-the-middle-index-in-array/)
|
||||
/// + Related Topics
|
||||
/// * 数组
|
||||
/// * 前缀和
|
||||
/// * 👍 371
|
||||
/// * 👎 0
|
||||
pub fn pivot_index(nums: Vec<i32>) -> i32 {
|
||||
let mut sum_right = nums.iter().sum::<i32>();
|
||||
let mut sum_left = 0;
|
||||
for i in 0..nums.len() {
|
||||
sum_right -= nums[i];
|
||||
if sum_left == sum_right {
|
||||
return i as i32;
|
||||
}
|
||||
sum_left += nums[i];
|
||||
}
|
||||
-1
|
||||
}
|
||||
}
|
||||
|
||||
#[cfg(test)]
|
||||
mod test {
|
||||
use crate::Solution;
|
||||
|
||||
#[test]
|
||||
fn test_q0724() {
|
||||
assert_eq!(Solution::pivot_index(vec![1, 7, 3, 6, 5, 6]), 3);
|
||||
}
|
||||
}
|
||||
|
|
@ -0,0 +1,96 @@
|
|||
use crate::Solution;
|
||||
|
||||
impl Solution {
|
||||
/// [778.水位上升的泳池中游泳](https://leetcode-cn.com/problems/swim-in-rising-water/)
|
||||
///
|
||||
/// 2022-02-21 17:14:26
|
||||
///
|
||||
/// 在一个 `n x n` 的整数矩阵 `grid` 中,每一个方格的值 `grid[i][j]` 表示位置 `(i, j)` 的平台高度。
|
||||
///
|
||||
/// 当开始下雨时,在时间为 `t` 时,水池中的水位为 `t` 。你可以从一个平台游向四周相邻的任意一个平台,但是前提是此时水位必须同时淹没这两个平台。假定你可以瞬间移动无限距离,也就是默认在方格内部游动是不耗时的。当然,在你游泳的时候你必须待在坐标方格里面。
|
||||
///
|
||||
/// 你从坐标方格的左上平台 `(0,0)` 出发。返回 _你到达坐标方格的右下平台 `(n-1, n-1)` 所需的最少时间 。_
|
||||
///
|
||||
/// + **示例 1:**
|
||||
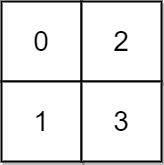
/// - 
|
||||
/// - **输入:** grid = \[\[0,2\],\[1,3\]\]
|
||||
/// - **输出:** 3
|
||||
/// - **解释:**
|
||||
/// - 时间为0时,你位于坐标方格的位置为 `(0, 0)。`
|
||||
/// - 此时你不能游向任意方向,因为四个相邻方向平台的高度都大于当前时间为 0 时的水位。
|
||||
/// - 等时间到达 3 时,你才可以游向平台 (1, 1). 因为此时的水位是 3,坐标方格中的平台没有比水位 3 更高的,所以你可以游向坐标方格中的任意位置
|
||||
/// + **示例 2:**
|
||||
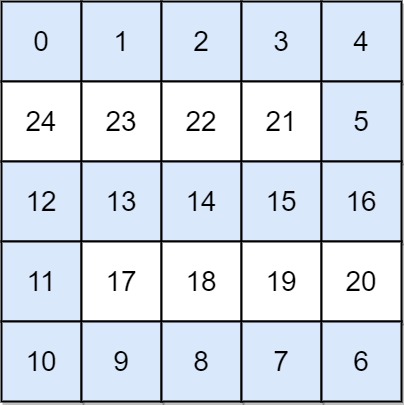
/// - 
|
||||
/// - **输入:** grid = \[\[0,1,2,3,4\],\[24,23,22,21,5\],\[12,13,14,15,16\],\[11,17,18,19,20\],\[10,9,8,7,6\]\]
|
||||
/// - **输出:** 16
|
||||
/// - **解释:**
|
||||
/// - 最终的路线用加粗进行了标记。
|
||||
/// - 我们必须等到时间为 16,此时才能保证平台 (0, 0) 和 (4, 4) 是连通的
|
||||
/// + **提示:**
|
||||
/// * `n == grid.length`
|
||||
/// * `n == grid[i].length`
|
||||
/// * `1 <= n <= 50`
|
||||
/// * `0 <= grid[i][j] < n2`
|
||||
/// * `grid[i][j]` 中每个值 **均无重复**
|
||||
/// + Related Topics
|
||||
/// * 深度优先搜索
|
||||
/// * 广度优先搜索
|
||||
/// * 并查集
|
||||
/// * 数组
|
||||
/// * 二分查找
|
||||
/// * 矩阵
|
||||
/// * 堆(优先队列)
|
||||
/// * 👍 217
|
||||
/// * 👎 0
|
||||
pub fn swim_in_water(grid: Vec<Vec<i32>>) -> i32 {
|
||||
const DIRS: [(i32, i32); 4] = [(-1, 0), (1, 0), (0, -1), (0, 1)];
|
||||
#[derive(PartialEq, Eq)]
|
||||
struct Item(usize, usize, i32);
|
||||
impl PartialOrd for Item {
|
||||
fn partial_cmp(&self, other: &Self) -> Option<std::cmp::Ordering> {
|
||||
other.2.partial_cmp(&self.2)
|
||||
}
|
||||
}
|
||||
impl Ord for Item {
|
||||
fn cmp(&self, other: &Self) -> std::cmp::Ordering {
|
||||
other.2.cmp(&self.2)
|
||||
}
|
||||
}
|
||||
let n = grid.len();
|
||||
let mut queue = std::collections::binary_heap::BinaryHeap::<Item>::new();
|
||||
queue.push(Item(0, 0, grid[0][0]));
|
||||
let mut dist = vec![vec![(n * n) as i32; n]; n];
|
||||
dist[0][0] = grid[0][0];
|
||||
let mut visited = vec![vec![false; n]; n];
|
||||
while !queue.is_empty() {
|
||||
let Item(x, y, _) = queue.pop().unwrap();
|
||||
if visited[x][y] { continue; }
|
||||
if x == n - 1 && y == n - 1 { return dist[n - 1][n - 1]; }
|
||||
visited[x][y] = true;
|
||||
for (dx, dy) in DIRS.iter() {
|
||||
let (nx, ny) = ((x as i32 + dx) as usize, (y as i32 + dy) as usize);
|
||||
if nx < n && ny < n && !visited[nx][ny] && grid[nx][ny].max(dist[x][y]) < dist[nx][ny] {
|
||||
dist[nx][ny] = grid[nx][ny].max(dist[x][y]);
|
||||
queue.push(Item(nx, ny, grid[nx][ny]));
|
||||
}
|
||||
}
|
||||
}
|
||||
-1
|
||||
}
|
||||
}
|
||||
|
||||
#[cfg(test)]
|
||||
mod test {
|
||||
use crate::Solution;
|
||||
|
||||
#[test]
|
||||
fn test_q0778() {
|
||||
let grid = vec![
|
||||
vec![0, 1, 2, 3, 4],
|
||||
vec![24, 23, 22, 21, 5],
|
||||
vec![12, 13, 14, 15, 16],
|
||||
vec![11, 17, 18, 19, 20],
|
||||
vec![10, 9, 8, 7, 6]];
|
||||
assert_eq!(Solution::swim_in_water(grid), 16);
|
||||
}
|
||||
}
|
||||
|
|
@ -0,0 +1,170 @@
|
|||
use crate::Solution;
|
||||
|
||||
impl Solution {
|
||||
/// [803.打砖块](https://leetcode-cn.com/problems/bricks-falling-when-hit/)
|
||||
///
|
||||
/// 2022-02-21 17:21:08
|
||||
///
|
||||
/// 有一个 `m x n` 的二元网格 `grid` ,其中 `1` 表示砖块,`0` 表示空白。砖块 **稳定**(不会掉落)的前提是:
|
||||
///
|
||||
/// > 一块砖直接连接到网格的顶部,或者
|
||||
/// > 至少有一块相邻(4 个方向之一)砖块 **稳定** 不会掉落时
|
||||
///
|
||||
/// 给你一个数组 `hits` ,这是需要依次消除砖块的位置。每当消除 `hits[i] = (rowi, coli)` 位置上的砖块时,对应位置的砖块(若存在)会消失,然后其他的砖块可能因为这一消除操作而 **掉落** 。一旦砖块掉落,它会 **立即** 从网格 `grid` 中消失(即,它不会落在其他稳定的砖块上)。
|
||||
///
|
||||
/// 返回一个数组 `result` ,其中 `result[i]` 表示第 `i` 次消除操作对应掉落的砖块数目。
|
||||
///
|
||||
/// + **注意**,消除可能指向是没有砖块的空白位置,如果发生这种情况,则没有砖块掉落。
|
||||
/// + **示例 1:**
|
||||
/// + **输入:** grid = \[\[1,0,0,0\],\[1,1,1,0\]\], hits = \[\[1,0\]\]
|
||||
/// + **输出:** \[2\]
|
||||
/// + **解释:**
|
||||
/// - 网格开始为:
|
||||
/// - \[\[1,0,0,0\],
|
||||
/// - \[**1**,1,1,0\]\]
|
||||
/// - 消除 (1,0) 处加粗的砖块,得到网格:
|
||||
/// - \[\[1,0,0,0\]
|
||||
/// - \[0,**1**,**1**,0\]\]
|
||||
/// - 两个加粗的砖不再稳定,因为它们不再与顶部相连,也不再与另一个稳定的砖相邻,因此它们将掉落。得到网格:
|
||||
/// - \[\[1,0,0,0\],
|
||||
/// - \[0,0,0,0\]\]
|
||||
/// - 因此,结果为 \[2\] 。
|
||||
///
|
||||
/// + **示例 2:**
|
||||
///
|
||||
/// + **输入:** grid = \[\[1,0,0,0\],\[1,1,0,0\]\], hits = \[\[1,1\],\[1,0\]\]
|
||||
/// + **输出:** \[0,0\]
|
||||
/// + **解释:**
|
||||
/// - 网格开始为:
|
||||
/// - \[\[1,0,0,0\],
|
||||
/// - \[1,**1**,0,0\]\]
|
||||
/// - 消除 (1,1) 处加粗的砖块,得到网格:
|
||||
/// - \[\[1,0,0,0\],
|
||||
/// - \[1,0,0,0\]\]
|
||||
/// - 剩下的砖都很稳定,所以不会掉落。网格保持不变:
|
||||
/// - \[\[1,0,0,0\],
|
||||
/// - \[**1**,0,0,0\]\]
|
||||
/// - 接下来消除 (1,0) 处加粗的砖块,得到网格:
|
||||
/// - \[\[1,0,0,0\],
|
||||
/// - \[0,0,0,0\]\]
|
||||
/// - 剩下的砖块仍然是稳定的,所以不会有砖块掉落。
|
||||
/// - 因此,结果为 \[0,0\] 。
|
||||
///
|
||||
/// + **提示:**
|
||||
/// * `m == grid.length`
|
||||
/// * `n == grid[i].length`
|
||||
/// * `1 <= m, n <= 200`
|
||||
/// * `grid[i][j]` 为 `0` 或 `1`
|
||||
/// * `1 <= hits.length <= 4 * 104`
|
||||
/// * `hits[i].length == 2`
|
||||
/// * `0 <= xi <= m - 1`
|
||||
/// * `0 <= yi <= n - 1`
|
||||
/// * 所有 `(xi, yi)` 互不相同
|
||||
/// + Related Topics
|
||||
/// * 并查集
|
||||
/// * 数组
|
||||
/// * 矩阵
|
||||
/// * 👍 226
|
||||
/// * 👎 0
|
||||
pub fn hit_bricks(grid: Vec<Vec<i32>>, hits: Vec<Vec<i32>>) -> Vec<i32> {
|
||||
const DIRECTIONS: [[i32; 2]; 4] = [[0, 1], [1, 0], [-1, 0], [0, -1]];
|
||||
let rows = grid.len();
|
||||
let cols = grid[0].len();
|
||||
let mut copy = grid.clone();
|
||||
for hit in &hits {
|
||||
copy[hit[0] as usize][hit[1] as usize] = 0;
|
||||
}
|
||||
let grid_len = rows * cols;
|
||||
|
||||
let mut parent = (0..(grid_len + 1)).collect::<Vec<usize>>();
|
||||
let mut size = vec![1usize; grid_len + 1];
|
||||
|
||||
fn in_area(x: usize, y: usize, rows: usize, cols: usize) -> bool {
|
||||
x < rows && y < cols
|
||||
}
|
||||
fn get_idx(x: usize, y: usize, cols: usize) -> usize {
|
||||
x * cols + y
|
||||
}
|
||||
fn find(parent: &mut Vec<usize>, x: usize) -> usize {
|
||||
if x != parent[x] {
|
||||
parent[x] = find(parent, parent[x]);
|
||||
}
|
||||
parent[x]
|
||||
}
|
||||
fn union(parent: &mut Vec<usize>, size: &mut Vec<usize>, x: usize, y: usize) {
|
||||
let root_x = find(parent, x);
|
||||
let root_y = find(parent, y);
|
||||
if root_x == root_y {
|
||||
return;
|
||||
}
|
||||
parent[root_x] = root_y;
|
||||
size[root_y] += size[root_x];
|
||||
}
|
||||
fn get_size(parent: &mut Vec<usize>, size: &mut Vec<usize>, x: usize) -> usize {
|
||||
return size[find(parent, x)];
|
||||
}
|
||||
|
||||
for j in 0..cols {
|
||||
if copy[0][j] == 1 {
|
||||
union(&mut parent, &mut size, j, grid_len);
|
||||
}
|
||||
}
|
||||
|
||||
for i in 1..rows {
|
||||
for j in 0..cols {
|
||||
if copy[i][j] == 1 {
|
||||
if copy[i - 1][j] == 1 {
|
||||
union(&mut parent, &mut size, get_idx(i - 1, j, cols), get_idx(i, j, cols));
|
||||
}
|
||||
if j > 0 && copy[i][j - 1] == 1 {
|
||||
union(&mut parent, &mut size, get_idx(i, j - 1, cols), get_idx(i, j, cols));
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
let mut res = vec![0i32; hits.len()];
|
||||
for i in (0..res.len()).rev() {
|
||||
let x = hits[i][0] as usize;
|
||||
let y = hits[i][1] as usize;
|
||||
if grid[x][y] == 0 {
|
||||
continue;
|
||||
}
|
||||
let origin = get_size(&mut parent, &mut size, grid_len);
|
||||
|
||||
if x == 0 {
|
||||
union(&mut parent, &mut size, y, grid_len);
|
||||
}
|
||||
|
||||
for direction in &DIRECTIONS {
|
||||
let new_x = (x as i32 + direction[0]) as usize;
|
||||
let new_y = (y as i32 + direction[1]) as usize;
|
||||
if in_area(new_x, new_y, rows, cols) && copy[new_x][new_y] == 1 {
|
||||
union(&mut parent, &mut size, get_idx(x, y, cols), get_idx(new_x, new_y, cols));
|
||||
}
|
||||
}
|
||||
|
||||
let current = get_size(&mut parent, &mut size, grid_len);
|
||||
res[i] = if current < origin + 1 {
|
||||
0
|
||||
} else {
|
||||
(current - origin - 1) as i32
|
||||
};
|
||||
copy[x][y] = 1;
|
||||
}
|
||||
res
|
||||
}
|
||||
}
|
||||
|
||||
#[cfg(test)]
|
||||
mod test {
|
||||
use crate::Solution;
|
||||
|
||||
#[test]
|
||||
fn test_q0803() {
|
||||
let grid = vec![vec![1, 0, 0, 0], vec![1, 1, 1, 0]];
|
||||
let hits = vec![vec![1, 0]];
|
||||
let vec1 = Solution::hit_bricks(grid, hits);
|
||||
//println!("{:?}", vec1);
|
||||
assert_eq!(vec1, vec![2]);
|
||||
}
|
||||
}
|
||||
|
|
@ -0,0 +1,67 @@
|
|||
use crate::Solution;
|
||||
|
||||
impl Solution {
|
||||
/// [830.较大分组的位置](https://leetcode-cn.com/problems/positions-of-large-groups/)
|
||||
///
|
||||
/// 2022-02-21 17:26:39
|
||||
///
|
||||
/// 在一个由小写字母构成的字符串 `s` 中,包含由一些连续的相同字符所构成的分组。
|
||||
///
|
||||
/// 例如,在字符串 `s = "abbxxxxzyy"` 中,就含有 `"a"`, `"bb"`, `"xxxx"`, `"z"` 和 `"yy"` 这样的一些分组。
|
||||
///
|
||||
/// 分组可以用区间 `[start, end]` 表示,其中 `start` 和 `end` 分别表示该分组的起始和终止位置的下标。上例中的 `"xxxx"` 分组用区间表示为 `[3,6]` 。
|
||||
///
|
||||
/// 我们称所有包含大于或等于三个连续字符的分组为 **较大分组** 。
|
||||
///
|
||||
/// 找到每一个 **较大分组** 的区间,**按起始位置下标递增顺序排序后**,返回结果。
|
||||
///
|
||||
/// + **示例 1:**
|
||||
/// + **输入:** s = "abbxxxxzzy"
|
||||
/// + **输出:** \[\[3,6\]\]
|
||||
/// + **解释:** `"xxxx" 是一个起始于 3 且终止于 6 的较大分组`。
|
||||
/// + **示例 2:**
|
||||
/// + **输入:** s = "abc"
|
||||
/// + **输出:** \[\]
|
||||
/// + **解释:** "a","b" 和 "c" 均不是符合要求的较大分组。
|
||||
/// + **示例 3:**
|
||||
/// + **输入:** s = "abcdddeeeeaabbbcd"
|
||||
/// + **输出:** \[\[3,5\],\[6,9\],\[12,14\]\]
|
||||
/// + **解释:** 较大分组为 "ddd", "eeee" 和 "bbb"
|
||||
/// + **示例 4:**
|
||||
/// + **输入:** s = "aba"
|
||||
/// + **输出:** \[\]
|
||||
/// + **提示:**
|
||||
/// * `1 <= s.length <= 1000`
|
||||
/// * `s` 仅含小写英文字母
|
||||
/// + Related Topics
|
||||
/// * 字符串
|
||||
/// * 👍 128
|
||||
/// * 👎 0
|
||||
pub fn large_group_positions(s: String) -> Vec<Vec<i32>> {
|
||||
let c = s.into_bytes();
|
||||
let mut start = 0i32;
|
||||
let mut res = vec![];
|
||||
for i in 1..=c.len() {
|
||||
if i == c.len() || c[i - 1] != c[i] {
|
||||
if i as i32 - start >= 3 {
|
||||
res.push(vec![start, (i - 1) as i32]);
|
||||
}
|
||||
start = i as i32;
|
||||
}
|
||||
}
|
||||
res
|
||||
}
|
||||
}
|
||||
|
||||
#[cfg(test)]
|
||||
mod test {
|
||||
use crate::Solution;
|
||||
|
||||
#[test]
|
||||
fn test_q0830() {
|
||||
let s = "abcdddeeeeaabbbcd".to_string();
|
||||
let vec = Solution::large_group_positions(s);
|
||||
//println!("{:?}", vec);
|
||||
assert_eq!(vec, vec![vec![3, 5], vec![6, 9], vec![12, 14]]);
|
||||
}
|
||||
}
|
||||
|
|
@ -0,0 +1,77 @@
|
|||
use crate::Solution;
|
||||
|
||||
impl Solution {
|
||||
/// [839.相似字符串组](https://leetcode-cn.com/problems/similar-string-groups/)
|
||||
///
|
||||
/// 2022-02-21 17:29:36
|
||||
///
|
||||
/// 如果交换字符串 `X` 中的两个不同位置的字母,使得它和字符串 `Y` 相等,那么称 `X` 和 `Y` 两个字符串相似。如果这两个字符串本身是相等的,那它们也是相似的。
|
||||
///
|
||||
/// 例如,`"tars"` 和 `"rats"` 是相似的 (交换 `0` 与 `2` 的位置); `"rats"` 和 `"arts"` 也是相似的,但是 `"star"` 不与 `"tars"`,`"rats"`,或 `"arts"` 相似。
|
||||
///
|
||||
/// 总之,它们通过相似性形成了两个关联组:`{"tars", "rats", "arts"}` 和 `{"star"}`。注意,`"tars"` 和 `"arts"` 是在同一组中,即使它们并不相似。形式上,对每个组而言,要确定一个单词在组中,只需要这个词和该组中至少一个单词相似。
|
||||
///
|
||||
/// 给你一个字符串列表 `strs`。列表中的每个字符串都是 `strs` 中其它所有字符串的一个字母异位词。请问 `strs` 中有多少个相似字符串组?
|
||||
///
|
||||
/// + **示例 1:**
|
||||
/// + **输入:** strs = \["tars","rats","arts","star"\]
|
||||
/// + **输出:** 2
|
||||
/// + **示例 2:**
|
||||
/// + **输入:** strs = \["omv","ovm"\]
|
||||
/// + **输出:** 1
|
||||
/// + **提示:**
|
||||
/// * `1 <= strs.length <= 300`
|
||||
/// * `1 <= strs[i].length <= 300`
|
||||
/// * `strs[i]` 只包含小写字母。
|
||||
/// * `strs` 中的所有单词都具有相同的长度,且是彼此的字母异位词。
|
||||
/// + Related Topics
|
||||
/// * 深度优先搜索
|
||||
/// * 广度优先搜索
|
||||
/// * 并查集
|
||||
/// * 字符串
|
||||
/// * 👍 139
|
||||
/// * 👎 0
|
||||
pub fn num_similar_groups(strs: Vec<String>) -> i32 {
|
||||
fn find(parent: &mut Vec<usize>, x: usize) -> usize {
|
||||
if parent[x] == x {
|
||||
x
|
||||
} else {
|
||||
parent[x] = find(parent, parent[x]);
|
||||
parent[x]
|
||||
}
|
||||
}
|
||||
fn check(a: &Vec<u8>, b: &Vec<u8>, len: usize) -> bool {
|
||||
let mut num = 0;
|
||||
for i in 0..len {
|
||||
if a[i] != b[i] {
|
||||
num += 1;
|
||||
if num > 2 { return false; }
|
||||
}
|
||||
}
|
||||
true
|
||||
}
|
||||
let (n, m) = (strs.len(), strs[0].len());
|
||||
let mut parent = (0..n).collect::<Vec<usize>>();
|
||||
let bytes_arr = strs.into_iter().map(|s| s.into_bytes()).collect::<Vec<Vec<u8>>>();
|
||||
for i in 0..n {
|
||||
for j in i + 1..n {
|
||||
let (fi, fj) = (find(&mut parent, i), find(&mut parent, j));
|
||||
if fi == fj { continue; }
|
||||
if check(&bytes_arr[i], &bytes_arr[j], m) {
|
||||
parent[fi] = fj;
|
||||
}
|
||||
}
|
||||
}
|
||||
parent.into_iter().enumerate().filter(|(i, n)| *i == *n).count() as i32
|
||||
}
|
||||
}
|
||||
|
||||
#[cfg(test)]
|
||||
mod test {
|
||||
use crate::Solution;
|
||||
|
||||
#[test]
|
||||
fn test_q0839() {
|
||||
assert_eq!(Solution::num_similar_groups(vec!["tars".to_string(), "rats".to_string(), "arts".to_string(), "star".to_string()]), 2);
|
||||
}
|
||||
}
|
||||
|
|
@ -0,0 +1,62 @@
|
|||
use crate::Solution;
|
||||
|
||||
impl Solution {
|
||||
/// [888.公平的糖果交换](https://leetcode-cn.com/problems/fair-candy-swap/)
|
||||
///
|
||||
/// 2022-02-21 17:30:15
|
||||
///
|
||||
/// 爱丽丝和鲍勃拥有不同总数量的糖果。给你两个数组 `aliceSizes` 和 `bobSizes` ,`aliceSizes[i]` 是爱丽丝拥有的第 `i` 盒糖果中的糖果数量,`bobSizes[j]` 是鲍勃拥有的第 `j` 盒糖果中的糖果数量。
|
||||
///
|
||||
/// 两人想要互相交换一盒糖果,这样在交换之后,他们就可以拥有相同总数量的糖果。一个人拥有的糖果总数量是他们每盒糖果数量的总和。
|
||||
///
|
||||
/// 返回一个整数数组 `answer`,其中 `answer[0]` 是爱丽丝必须交换的糖果盒中的糖果的数目,`answer[1]` 是鲍勃必须交换的糖果盒中的糖果的数目。如果存在多个答案,你可以返回其中 **任何一个** 。题目测试用例保证存在与输入对应的答案。
|
||||
///
|
||||
/// + **示例 1:**
|
||||
/// + **输入:** aliceSizes = \[1,1\], bobSizes = \[2,2\]
|
||||
/// + **输出:** \[1,2\]
|
||||
/// + **示例 2:**
|
||||
/// + **输入:** aliceSizes = \[1,2\], bobSizes = \[2,3\]
|
||||
/// + **输出:** \[1,2\]
|
||||
/// + **示例 3:**
|
||||
/// + **输入:** aliceSizes = \[2\], bobSizes = \[1,3\]
|
||||
/// + **输出:** \[2,3\]
|
||||
/// + **示例 4:**
|
||||
/// + **输入:** aliceSizes = \[1,2,5\], bobSizes = \[2,4\]
|
||||
/// + **输出:** \[5,4\]
|
||||
/// + **提示:**
|
||||
/// * `1 <= aliceSizes.length, bobSizes.length <= 104`
|
||||
/// * `1 <= aliceSizes[i], bobSizes[j] <= 105`
|
||||
/// * 爱丽丝和鲍勃的糖果总数量不同。
|
||||
/// * 题目数据保证对于给定的输入至少存在一个有效答案。
|
||||
/// + Related Topics
|
||||
/// * 数组
|
||||
/// * 哈希表
|
||||
/// * 二分查找
|
||||
/// * 排序
|
||||
/// * 👍 189
|
||||
/// * 👎 0
|
||||
pub fn fair_candy_swap(alice_sizes: Vec<i32>, bob_sizes: Vec<i32>) -> Vec<i32> {
|
||||
use std::iter::FromIterator;
|
||||
let delta = (alice_sizes.iter().sum::<i32>() - bob_sizes.iter().sum::<i32>()) / 2;
|
||||
let set = std::collections::HashSet::<i32>::from_iter(alice_sizes.into_iter());
|
||||
let mut ans = vec![];
|
||||
for y in bob_sizes {
|
||||
let x = y + delta;
|
||||
if set.contains(&x) {
|
||||
ans = vec![x, y];
|
||||
break;
|
||||
}
|
||||
}
|
||||
ans
|
||||
}
|
||||
}
|
||||
|
||||
#[cfg(test)]
|
||||
mod test {
|
||||
use crate::Solution;
|
||||
|
||||
#[test]
|
||||
fn test_q0888() {
|
||||
assert_eq!(Solution::fair_candy_swap(vec![1, 2], vec![2, 3]), vec![1, 2]);
|
||||
}
|
||||
}
|
||||
|
|
@ -0,0 +1,89 @@
|
|||
use crate::Solution;
|
||||
|
||||
impl Solution {
|
||||
/// [947.移除最多的同行或同列石头](https://leetcode-cn.com/problems/most-stones-removed-with-same-row-or-column/)
|
||||
///
|
||||
/// 2022-02-21 17:39:09
|
||||
///
|
||||
/// `n` 块石头放置在二维平面中的一些整数坐标点上。每个坐标点上最多只能有一块石头。
|
||||
///
|
||||
/// 如果一块石头的 **同行或者同列** 上有其他石头存在,那么就可以移除这块石头。
|
||||
///
|
||||
/// 给你一个长度为 `n` 的数组 `stones` ,其中 `stones[i] = [xi, yi]` 表示第 `i` 块石头的位置,返回 **可以移除的石子** 的最大数量。
|
||||
///
|
||||
/// + **示例 1:**
|
||||
/// + **输入:** stones = \[\[0,0\],\[0,1\],\[1,0\],\[1,2\],\[2,1\],\[2,2\]\]
|
||||
/// + **输出:** 5
|
||||
/// + **解释:** 一种移除 5 块石头的方法如下所示:
|
||||
/// 1. 移除石头 \[2,2\] ,因为它和 \[2,1\] 同行。
|
||||
/// 2. 移除石头 \[2,1\] ,因为它和 \[0,1\] 同列。
|
||||
/// 3. 移除石头 \[1,2\] ,因为它和 \[1,0\] 同行。
|
||||
/// 4. 移除石头 \[1,0\] ,因为它和 \[0,0\] 同列。
|
||||
/// 5. 移除石头 \[0,1\] ,因为它和 \[0,0\] 同行。
|
||||
///
|
||||
/// 石头 \[0,0\] 不能移除,因为它没有与另一块石头同行/列。
|
||||
/// + **示例 2:**
|
||||
/// + **输入:** stones = \[\[0,0\],\[0,2\],\[1,1\],\[2,0\],\[2,2\]\]
|
||||
/// + **输出:** 3
|
||||
/// + **解释:** 一种移除 3 块石头的方法如下所示:
|
||||
/// 1. 移除石头 \[2,2\] ,因为它和 \[2,0\] 同行。
|
||||
/// 2. 移除石头 \[2,0\] ,因为它和 \[0,0\] 同列。
|
||||
/// 3. 移除石头 \[0,2\] ,因为它和 \[0,0\] 同行。
|
||||
///
|
||||
/// 石头 \[0,0\] 和 \[1,1\] 不能移除,因为它们没有与另一块石头同行/列。
|
||||
/// + **示例 3:**
|
||||
/// + **输入:** stones = \[\[0,0\]\]
|
||||
/// + **输出:** 0
|
||||
/// + **解释:** \[0,0\] 是平面上唯一一块石头,所以不可以移除它。
|
||||
/// + **提示:**
|
||||
/// * `1 <= stones.length <= 1000`
|
||||
/// * `0 <= xi, yi <= 104`
|
||||
/// * 不会有两块石头放在同一个坐标点上
|
||||
/// + Related Topics
|
||||
/// * 深度优先搜索
|
||||
/// * 并查集
|
||||
/// * 图
|
||||
/// * 👍 256
|
||||
/// * 👎 0
|
||||
pub fn remove_stones(stones: Vec<Vec<i32>>) -> i32 {
|
||||
use std::collections::HashMap;
|
||||
let mut parent = HashMap::<usize, usize>::new();
|
||||
let mut count = 0usize;
|
||||
fn find(parent: &mut HashMap<usize, usize>, count: &mut usize, x: usize) -> usize {
|
||||
if !parent.contains_key(&x) {
|
||||
parent.insert(x, x);
|
||||
*count += 1;
|
||||
}
|
||||
if x != parent[&x] {
|
||||
let v = find(parent, count, parent[&x]);
|
||||
parent.insert(x, v);
|
||||
}
|
||||
parent[&x]
|
||||
}
|
||||
|
||||
for stone in &stones {
|
||||
let root_x = find(&mut parent, &mut count, !stone[0] as usize);
|
||||
let root_y = find(&mut parent, &mut count, stone[1] as usize);
|
||||
if root_x == root_y {
|
||||
continue;
|
||||
}
|
||||
parent.insert(root_x, root_y);
|
||||
count -= 1;
|
||||
}
|
||||
|
||||
(stones.len() - count) as i32
|
||||
}
|
||||
}
|
||||
|
||||
#[cfg(test)]
|
||||
mod test {
|
||||
use crate::Solution;
|
||||
|
||||
#[test]
|
||||
fn test_q0947() {
|
||||
let stones = vec![vec![0, 0], vec![0, 1], vec![1, 0], vec![1, 2], vec![2, 1], vec![2, 2]];
|
||||
let i = Solution::remove_stones(stones);
|
||||
//println!("{}", i);
|
||||
assert_eq!(i, 5);
|
||||
}
|
||||
}
|
||||
|
|
@ -0,0 +1,96 @@
|
|||
use crate::Solution;
|
||||
|
||||
impl Solution {
|
||||
/// [959.由斜杠划分区域](https://leetcode-cn.com/problems/regions-cut-by-slashes/)
|
||||
///
|
||||
/// 2022-02-21 17:47:06
|
||||
///
|
||||
/// 在由 `1 x 1` 方格组成的 `n x n` 网格 `grid` 中,每个 `1 x 1` 方块由 `'/'`、`'\'` 或空格构成。这些字符会将方块划分为一些共边的区域。
|
||||
///
|
||||
/// 给定网格 `grid` 表示为一个字符串数组,返回 _区域的数量_ 。
|
||||
///
|
||||
/// 请注意,反斜杠字符是转义的,因此 `'\'` 用 `'\\'` 表示。
|
||||
///
|
||||
/// + **示例 1:**
|
||||
/// + 
|
||||
/// + **输入:** grid = \[" /","/ "\]
|
||||
/// + **输出:** 2
|
||||
/// + **示例 2:**
|
||||
/// + 
|
||||
/// + **输入:** grid = \[" /"," "\]
|
||||
/// + **输出:** 1
|
||||
/// + **示例 3:**
|
||||
/// + 
|
||||
/// + **输入:** grid = \["/\\\\","\\\\/"\]
|
||||
/// + **输出:** 5
|
||||
/// + **解释:** 回想一下,因为 \\ 字符是转义的,所以 "/\\\\" 表示 /\\,而 "\\\\/" 表示 \\/。
|
||||
/// + **提示:**
|
||||
/// * `n == grid.length == grid[i].length`
|
||||
/// * `1 <= n <= 30`
|
||||
/// * `grid[i][j]` 是 `'/'`、`'\'`、或 `' '`
|
||||
/// + Related Topics
|
||||
/// * 深度优先搜索
|
||||
/// * 广度优先搜索
|
||||
/// * 并查集
|
||||
/// * 图
|
||||
/// * 👍 298
|
||||
/// * 👎 0
|
||||
pub fn regions_by_slashes(grid: Vec<String>) -> i32 {
|
||||
fn find(parent: &mut Vec<usize>, x: usize) -> usize {
|
||||
if parent[x] == x {
|
||||
x
|
||||
} else {
|
||||
parent[x] = find(parent, parent[x]);
|
||||
parent[x]
|
||||
}
|
||||
}
|
||||
fn union(parent: &mut Vec<usize>, x: usize, y: usize) {
|
||||
let x_root = find(parent, x);
|
||||
let y_root = find(parent, y);
|
||||
parent[x_root] = y_root;
|
||||
}
|
||||
let n = grid.len();
|
||||
let mut parent = (0..(n * n * 4)).collect::<Vec<usize>>();
|
||||
for (i, s) in grid.into_iter().enumerate() {
|
||||
let s = s.into_bytes();
|
||||
for j in 0..n {
|
||||
let idx = i * n + j;
|
||||
if i < n - 1 {
|
||||
let bottom = idx + n;
|
||||
union(&mut parent, idx * 4 + 2, bottom * 4);
|
||||
}
|
||||
if j < n - 1 {
|
||||
let right = idx + 1;
|
||||
union(&mut parent, idx * 4 + 1, right * 4 + 3);
|
||||
}
|
||||
if s[j] == b'/' {
|
||||
union(&mut parent, idx * 4, idx * 4 + 3);
|
||||
union(&mut parent, idx * 4 + 1, idx * 4 + 2);
|
||||
} else if s[j] == b'\\' {
|
||||
union(&mut parent, idx * 4, idx * 4 + 1);
|
||||
union(&mut parent, idx * 4 + 2, idx * 4 + 3);
|
||||
} else {
|
||||
union(&mut parent, idx * 4, idx * 4 + 1);
|
||||
union(&mut parent, idx * 4 + 1, idx * 4 + 2);
|
||||
union(&mut parent, idx * 4 + 2, idx * 4 + 3);
|
||||
}
|
||||
}
|
||||
}
|
||||
let mut fathers = std::collections::HashSet::<usize>::new();
|
||||
for i in 0..(n * n * 4) {
|
||||
let fa = find(&mut parent, i);
|
||||
fathers.insert(fa);
|
||||
}
|
||||
fathers.len() as i32
|
||||
}
|
||||
}
|
||||
|
||||
#[cfg(test)]
|
||||
mod test {
|
||||
use crate::Solution;
|
||||
|
||||
#[test]
|
||||
fn test_q0959() {
|
||||
assert_eq!(Solution::regions_by_slashes(vec!["/\\".to_string(), "\\/".to_string()]), 5);
|
||||
}
|
||||
}
|
||||
|
|
@ -0,0 +1,66 @@
|
|||
use crate::Solution;
|
||||
|
||||
impl Solution {
|
||||
/// [989.数组形式的整数加法](https://leetcode-cn.com/problems/add-to-array-form-of-integer/)
|
||||
///
|
||||
/// 2022-02-21 17:43:37
|
||||
///
|
||||
/// 整数的 **数组形式** `num` 是按照从左到右的顺序表示其数字的数组。
|
||||
///
|
||||
/// * 例如,对于 `num = 1321` ,数组形式是 `[1,3,2,1]` 。
|
||||
///
|
||||
/// 给定 `num` ,整数的 **数组形式** ,和整数 `k` ,返回 _整数 `num + k` 的 **数组形式**_ 。
|
||||
///
|
||||
/// + **示例 1:**
|
||||
/// + **输入:** num = \[1,2,0,0\], k = 34
|
||||
/// + **输出:** \[1,2,3,4\]
|
||||
/// + **解释:** 1200 + 34 = 1234
|
||||
/// + **示例 2:**
|
||||
/// + **输入:** num = \[2,7,4\], k = 181
|
||||
/// + **输出:** \[4,5,5\]
|
||||
/// + **解释:** 274 + 181 = 455
|
||||
/// + **示例 3:**
|
||||
/// + **输入:** num = \[2,1,5\], k = 806
|
||||
/// + **输出:** \[1,0,2,1\]
|
||||
/// + **解释:** 215 + 806 = 1021
|
||||
/// + **提示:**
|
||||
/// * `1 <= num.length <= 104`
|
||||
/// * `0 <= num[i] <= 9`
|
||||
/// * `num` 不包含任何前导零,除了零本身
|
||||
/// * `1 <= k <= 104`
|
||||
/// + Related Topics
|
||||
/// * 数组
|
||||
/// * 数学
|
||||
/// * 👍 184
|
||||
/// * 👎 0
|
||||
pub fn add_to_array_form(mut num: Vec<i32>, mut k: i32) -> Vec<i32> {
|
||||
let mut carry = 0;
|
||||
for n in num.iter_mut().rev() {
|
||||
*n = *n + k % 10 + carry;
|
||||
carry = *n / 10;
|
||||
k /= 10;
|
||||
*n %= 10;
|
||||
}
|
||||
while k != 0 || carry != 0 {
|
||||
carry = k % 10 + carry;
|
||||
num.insert(0, carry % 10);
|
||||
k /= 10;
|
||||
carry /= 10;
|
||||
}
|
||||
num
|
||||
}
|
||||
}
|
||||
|
||||
#[cfg(test)]
|
||||
mod test {
|
||||
use crate::Solution;
|
||||
|
||||
#[test]
|
||||
fn test_q0989() {
|
||||
let a = vec![1];
|
||||
let k = 9999;
|
||||
let b = Solution::add_to_array_form(a, k);
|
||||
//println!("{:?}", b);
|
||||
assert_eq!(b, vec![1, 0, 0, 0, 0]);
|
||||
}
|
||||
}
|
||||
|
|
@ -0,0 +1,55 @@
|
|||
use crate::Solution;
|
||||
|
||||
impl Solution {
|
||||
/// [1018.可被 5 整除的二进制前缀](https://leetcode-cn.com/problems/binary-prefix-divisible-by-5/)
|
||||
///
|
||||
/// 2022-02-21 17:59:17
|
||||
///
|
||||
/// 给定由若干 `0` 和 `1` 组成的数组 `A`。我们定义 `N_i`:从 `A[0]` 到 `A[i]` 的第 `i` 个子数组被解释为一个二进制数(从最高有效位到最低有效位)。
|
||||
///
|
||||
/// 返回布尔值列表 `answer`,只有当 `N_i` 可以被 `5` 整除时,答案 `answer[i]` 为 `true`,否则为 `false`。
|
||||
///
|
||||
/// + **示例 1:**
|
||||
/// + **输入:** \[0,1,1\]
|
||||
/// + **输出:** \[true,false,false\]
|
||||
/// + **解释:**
|
||||
/// - 输入数字为 0, 01, 011;也就是十进制中的 0, 1, 3 。只有第一个数可以被 5 整除,因此 answer\[0\] 为真。
|
||||
/// + **示例 2:**
|
||||
/// + **输入:** \[1,1,1\]
|
||||
/// + **输出:** \[false,false,false\]
|
||||
/// + **示例 3:**
|
||||
/// + **输入:** \[0,1,1,1,1,1\]
|
||||
/// + **输出:** \[true,false,false,false,true,false\]
|
||||
/// + **示例 4:**
|
||||
/// + **输入:** \[1,1,1,0,1\]
|
||||
/// + **输出:** \[false,false,false,false,false\]
|
||||
/// + **提示:**
|
||||
/// 1. `1 <= A.length <= 30000`
|
||||
/// 2. `A[i]` 为 `0` 或 `1`
|
||||
/// + Related Topics
|
||||
/// * 数组
|
||||
/// * 👍 137
|
||||
/// * 👎 0
|
||||
pub fn prefixes_div_by5(nums: Vec<i32>) -> Vec<bool> {
|
||||
let mut ret = Vec::<bool>::with_capacity(nums.len());
|
||||
let mut s = 0;
|
||||
for n in nums {
|
||||
s = ((s << 1) + n) % 5;
|
||||
ret.push(s == 0);
|
||||
}
|
||||
ret
|
||||
}
|
||||
}
|
||||
|
||||
#[cfg(test)]
|
||||
mod test {
|
||||
use crate::Solution;
|
||||
|
||||
#[test]
|
||||
fn test_q1018() {
|
||||
let a = vec![0, 1, 1, 1, 1, 1, 0, 1, 0];
|
||||
let by5 = Solution::prefixes_div_by5(a);
|
||||
//println!("{:?}", by5);
|
||||
assert_eq!(by5, vec![true, false, false, false, true, false, false, true, true]);
|
||||
}
|
||||
}
|
||||
|
|
@ -0,0 +1,49 @@
|
|||
use crate::Solution;
|
||||
|
||||
impl Solution {
|
||||
/// [1025.除数博弈](https://leetcode-cn.com/problems/divisor-game/)
|
||||
///
|
||||
/// 2022-02-21 17:56:00
|
||||
///
|
||||
/// 爱丽丝和鲍勃一起玩游戏,他们轮流行动。爱丽丝先手开局。
|
||||
///
|
||||
/// 最初,黑板上有一个数字 `n` 。在每个玩家的回合,玩家需要执行以下操作:
|
||||
///
|
||||
/// > 选出任一 `x`,满足 `0 < x < n` 且 `n % x == 0` 。
|
||||
/// > 用 `n - x` 替换黑板上的数字 `n` 。
|
||||
///
|
||||
/// 如果玩家无法执行这些操作,就会输掉游戏。
|
||||
///
|
||||
/// _只有在爱丽丝在游戏中取得胜利时才返回 `true` 。假设两个玩家都以最佳状态参与游戏。_
|
||||
///
|
||||
/// + **示例 1:**
|
||||
/// + **输入:** n = 2
|
||||
/// + **输出:** true
|
||||
/// + **解释:** 爱丽丝选择 1,鲍勃无法进行操作。
|
||||
/// + **示例 2:**
|
||||
/// + **输入:** n = 3
|
||||
/// + **输出:** false
|
||||
/// + **解释:** 爱丽丝选择 1,鲍勃也选择 1,然后爱丽丝无法进行操作。
|
||||
/// + **提示:**
|
||||
/// * `1 <= n <= 1000`
|
||||
/// + Related Topics
|
||||
/// * 脑筋急转弯
|
||||
/// * 数学
|
||||
/// * 动态规划
|
||||
/// * 博弈
|
||||
/// * 👍 342
|
||||
/// * 👎 0
|
||||
pub fn divisor_game(n: i32) -> bool {
|
||||
(n & 1) == 0
|
||||
}
|
||||
}
|
||||
|
||||
#[cfg(test)]
|
||||
mod test {
|
||||
use crate::Solution;
|
||||
|
||||
#[test]
|
||||
fn test_q1025() {
|
||||
assert_eq!(Solution::divisor_game(123), false);
|
||||
}
|
||||
}
|
||||
|
|
@ -0,0 +1,37 @@
|
|||
use crate::Solution;
|
||||
|
||||
impl Solution {
|
||||
/// [1108.IP 地址无效化](https://leetcode-cn.com/problems/defanging-an-ip-address/)
|
||||
///
|
||||
/// 2022-02-21 18:03:40
|
||||
///
|
||||
/// 给你一个有效的 [IPv4](https://baike.baidu.com/item/IPv4) 地址 `address`,返回这个 IP 地址的无效化版本。
|
||||
///
|
||||
/// 所谓无效化 IP 地址,其实就是用 `"[.]"` 代替了每个 `"."`。
|
||||
///
|
||||
/// + **示例 1:**
|
||||
/// + **输入:** address = "1.1.1.1"
|
||||
/// + **输出:** "1\[.\]1\[.\]1\[.\]1"
|
||||
/// + **示例 2:**
|
||||
/// + **输入:** address = "255.100.50.0"
|
||||
/// + **输出:** "255\[.\]100\[.\]50\[.\]0"
|
||||
/// + **提示:**
|
||||
/// * 给出的 `address` 是一个有效的 IPv4 地址
|
||||
/// + Related Topics
|
||||
/// * 字符串
|
||||
/// * 👍 77
|
||||
/// * 👎 0
|
||||
pub fn defang_i_paddr(address: String) -> String {
|
||||
address.replace(".", "[.]")
|
||||
}
|
||||
}
|
||||
|
||||
#[cfg(test)]
|
||||
mod test {
|
||||
use crate::Solution;
|
||||
|
||||
#[test]
|
||||
fn test_q1108() {
|
||||
assert_eq!(Solution::defang_i_paddr("1.1.1.1".to_string()), "1[.]1[.]1[.]1".to_string());
|
||||
}
|
||||
}
|
||||
|
|
@ -0,0 +1,52 @@
|
|||
use crate::Solution;
|
||||
|
||||
impl Solution {
|
||||
/// [1128.等价多米诺骨牌对的数量](https://leetcode-cn.com/problems/number-of-equivalent-domino-pairs/)
|
||||
///
|
||||
/// 2022-02-21 18:06:48
|
||||
///
|
||||
/// 给你一个由一些多米诺骨牌组成的列表 `dominoes`。
|
||||
///
|
||||
/// 如果其中某一张多米诺骨牌可以通过旋转 `0` 度或 `180` 度得到另一张多米诺骨牌,我们就认为这两张牌是等价的。
|
||||
///
|
||||
/// 形式上,`dominoes[i] = [a, b]` 和 `dominoes[j] = [c, d]` 等价的前提是 `a==c` 且 `b==d`,或是 `a==d` 且 `b==c`。
|
||||
///
|
||||
/// 在 `0 <= i < j < dominoes.length` 的前提下,找出满足 `dominoes[i]` 和 `dominoes[j]` 等价的骨牌对 `(i, j)` 的数量。
|
||||
///
|
||||
/// + **示例:**
|
||||
/// + **输入:** dominoes = \[\[1,2\],\[2,1\],\[3,4\],\[5,6\]\]
|
||||
/// + **输出:** 1
|
||||
/// + **提示:**
|
||||
/// * `1 <= dominoes.length <= 40000`
|
||||
/// * `1 <= dominoes[i][j] <= 9`
|
||||
/// + Related Topics
|
||||
/// * 数组
|
||||
/// * 哈希表
|
||||
/// * 计数
|
||||
/// * 👍 136
|
||||
/// * 👎 0
|
||||
pub fn num_equiv_domino_pairs(dominoes: Vec<Vec<i32>>) -> i32 {
|
||||
let mut m = std::collections::HashMap::<i32, i32>::new();
|
||||
let mut ret = 0;
|
||||
for d in dominoes {
|
||||
let key = if d[0] < d[1] {
|
||||
d[0] * 10 + d[1]
|
||||
} else {
|
||||
d[1] * 10 + d[0]
|
||||
};
|
||||
ret += m.get(&key).unwrap_or(&0);
|
||||
*m.entry(key).or_default() += 1;
|
||||
}
|
||||
ret
|
||||
}
|
||||
}
|
||||
|
||||
#[cfg(test)]
|
||||
mod test {
|
||||
use crate::Solution;
|
||||
|
||||
#[test]
|
||||
fn test_q1128() {
|
||||
assert_eq!(Solution::num_equiv_domino_pairs(vec![vec![1,2],vec![2,1],vec![3,4],vec![5,6]]), 1);
|
||||
}
|
||||
}
|
||||
|
|
@ -0,0 +1,118 @@
|
|||
use crate::Solution;
|
||||
|
||||
impl Solution {
|
||||
/// [1202.交换字符串中的元素](https://leetcode-cn.com/problems/smallest-string-with-swaps/)
|
||||
///
|
||||
/// 2022-02-21 18:11:46
|
||||
///
|
||||
/// 给你一个字符串 `s`,以及该字符串中的一些「索引对」数组 `pairs`,其中 `pairs[i] = [a, b]` 表示字符串中的两个索引(编号从 0 开始)。
|
||||
///
|
||||
/// 你可以 **任意多次交换** 在 `pairs` 中任意一对索引处的字符。
|
||||
///
|
||||
/// 返回在经过若干次交换后,`s` 可以变成的按字典序最小的字符串。
|
||||
///
|
||||
/// + **示例 1:**
|
||||
/// + **输入:** s = "dcab", pairs = \[\[0,3\],\[1,2\]\]
|
||||
/// + **输出:** "bacd"
|
||||
/// + **解释:**
|
||||
/// - 交换 s\[0\] 和 s\[3\], s = "bcad"
|
||||
/// - 交换 s\[1\] 和 s\[2\], s = "bacd"
|
||||
/// + **示例 2:**
|
||||
/// + **输入:** s = "dcab", pairs = \[\[0,3\],\[1,2\],\[0,2\]\]
|
||||
/// + **输出:** "abcd"
|
||||
/// + **解释:**
|
||||
/// - 交换 s\[0\] 和 s\[3\], s = "bcad"
|
||||
/// - 交换 s\[0\] 和 s\[2\], s = "acbd"
|
||||
/// - 交换 s\[1\] 和 s\[2\], s = "abcd"
|
||||
/// + **示例 3:**
|
||||
/// + **输入:** s = "cba", pairs = \[\[0,1\],\[1,2\]\]
|
||||
/// + **输出:** "abc"
|
||||
/// + **解释:**
|
||||
/// - 交换 s\[0\] 和 s\[1\], s = "bca"
|
||||
/// - 交换 s\[1\] 和 s\[2\], s = "bac"
|
||||
/// - 交换 s\[0\] 和 s\[1\], s = "abc"
|
||||
/// + **提示:**
|
||||
/// * `1 <= s.length <= 10^5`
|
||||
/// * `0 <= pairs.length <= 10^5`
|
||||
/// * `0 <= pairs[i][0], pairs[i][1] < s.length`
|
||||
/// * `s` 中只含有小写英文字母
|
||||
/// + Related Topics
|
||||
/// * 深度优先搜索
|
||||
/// * 广度优先搜索
|
||||
/// * 并查集
|
||||
/// * 哈希表
|
||||
/// * 字符串
|
||||
/// * 👍 256
|
||||
/// * 👎 0
|
||||
pub fn smallest_string_with_swaps(s: String, pairs: Vec<Vec<i32>>) -> String {
|
||||
if pairs.is_empty() {
|
||||
return s;
|
||||
}
|
||||
|
||||
use std::collections::HashMap;
|
||||
use std::collections::binary_heap::BinaryHeap;
|
||||
use std::cmp::Reverse;
|
||||
let len = s.len();
|
||||
|
||||
let mut parent = (0..len).collect::<Vec<usize>>();
|
||||
let mut rank = vec![1usize; len];
|
||||
|
||||
fn find(parent: &mut Vec<usize>, x: usize) -> usize {
|
||||
if x != parent[x] {
|
||||
parent[x] = find(parent, parent[x]);
|
||||
}
|
||||
return parent[x];
|
||||
}
|
||||
|
||||
fn union(parent: &mut Vec<usize>, rank: &mut Vec<usize>, x: usize, y: usize) {
|
||||
let root_x = find(parent, x);
|
||||
let root_y = find(parent, y);
|
||||
if root_x == root_y {
|
||||
return;
|
||||
}
|
||||
if rank[root_x] == rank[root_y] {
|
||||
parent[root_x] = root_y;
|
||||
rank[root_y] += 1;
|
||||
} else if rank[root_x] < rank[root_y] {
|
||||
parent[root_x] = parent[root_y];
|
||||
} else {
|
||||
parent[root_y] = parent[root_x];
|
||||
}
|
||||
}
|
||||
|
||||
for pair in pairs {
|
||||
union(&mut parent, &mut rank, pair[0] as usize, pair[1] as usize);
|
||||
}
|
||||
|
||||
let s = s.into_bytes();
|
||||
let mut map = HashMap::<usize, BinaryHeap<Reverse<u8>>>::new();
|
||||
for i in 0..len {
|
||||
let root = find(&mut parent, i);
|
||||
if map.contains_key(&root) {
|
||||
map.get_mut(&root).unwrap().push(Reverse(s[i]));
|
||||
} else {
|
||||
let mut min_heap = BinaryHeap::<Reverse<u8>>::new();
|
||||
min_heap.push(Reverse(s[i]));
|
||||
map.insert(root, min_heap);
|
||||
}
|
||||
}
|
||||
|
||||
let mut ret = String::with_capacity(len);
|
||||
for i in 0..len {
|
||||
let root = find(&mut parent, i);
|
||||
let c = map.get_mut(&root).unwrap().pop().unwrap().0;
|
||||
ret.push(c as char);
|
||||
}
|
||||
ret
|
||||
}
|
||||
}
|
||||
|
||||
#[cfg(test)]
|
||||
mod test {
|
||||
use crate::Solution;
|
||||
|
||||
#[test]
|
||||
fn test_q1202() {
|
||||
assert_eq!(Solution::smallest_string_with_swaps("dcab".to_string(), vec![vec![0,3],vec![1,2],vec![0,2]]), "abcd".to_string());
|
||||
}
|
||||
}
|
||||
|
|
@ -27,24 +27,6 @@ impl Solution {
|
|||
true
|
||||
}
|
||||
|
||||
/// 1025.除数博弈
|
||||
///
|
||||
/// [原题链接](https://leetcode-cn.com/problems/divisor-game/)
|
||||
///
|
||||
/// 偶赢奇输
|
||||
pub fn divisor_game(n: i32) -> bool {
|
||||
(n & 1) == 0
|
||||
}
|
||||
|
||||
/// 693.交替位二进制数
|
||||
///
|
||||
/// [原题链接](https://leetcode-cn.com/problems/binary-number-with-alternating-bits/)
|
||||
///
|
||||
pub fn has_alternating_bits(n: i32) -> bool {
|
||||
let n = (n ^ (n >> 1));
|
||||
(n as i64 & (n as i64 + 1)) == 0
|
||||
}
|
||||
|
||||
/// 面试题 16.01.交换数字
|
||||
///
|
||||
/// [原题链接](https://leetcode-cn.com/problems/swap-numbers-lcci/)
|
||||
|
|
@ -130,13 +112,6 @@ impl Solution {
|
|||
}).collect()
|
||||
}
|
||||
|
||||
/// 1108.IP 地址无效化
|
||||
///
|
||||
/// [原题链接](https://leetcode-cn.com/problems/defanging-an-ip-address/)
|
||||
pub fn defang_i_paddr(address: String) -> String {
|
||||
address.replace(".", "[.]")
|
||||
}
|
||||
|
||||
/// 1281.整数的各位积和之差
|
||||
///
|
||||
/// [原题链接](https://leetcode-cn.com/problems/subtract-the-product-and-sum-of-digits-of-an-integer/)
|
||||
|
|
@ -316,24 +291,6 @@ impl Solution {
|
|||
res + num
|
||||
}
|
||||
|
||||
/// 830.较大分组的位置
|
||||
///
|
||||
/// [原题链接](https://leetcode-cn.com/problems/positions-of-large-groups/)
|
||||
pub fn large_group_positions(s: String) -> Vec<Vec<i32>> {
|
||||
let c = s.into_bytes();
|
||||
let mut start = 0i32;
|
||||
let mut res = vec![];
|
||||
for i in 1..=c.len() {
|
||||
if i == c.len() || c[i - 1] != c[i] {
|
||||
if i as i32 - start >= 3 {
|
||||
res.push(vec![start, (i - 1) as i32]);
|
||||
}
|
||||
start = i as i32;
|
||||
}
|
||||
}
|
||||
res
|
||||
}
|
||||
|
||||
/// 1678.设计 Goal 解析器
|
||||
///
|
||||
/// [原题链接](https://leetcode-cn.com/problems/goal-parser-interpretation/)
|
||||
|
|
@ -432,331 +389,6 @@ impl Solution {
|
|||
unimplemented!()
|
||||
}
|
||||
|
||||
/// 1202.交换字符串中的元素
|
||||
///
|
||||
/// [原题链接](https://leetcode-cn.com/problems/smallest-string-with-swaps/)
|
||||
/// # 方法1 并查集 优先队列
|
||||
///
|
||||
/// # 方法2 DFS
|
||||
///
|
||||
/// ## 源码
|
||||
pub fn smallest_string_with_swaps(s: String, pairs: Vec<Vec<i32>>) -> String {
|
||||
if pairs.is_empty() {
|
||||
return s;
|
||||
}
|
||||
|
||||
use std::collections::HashMap;
|
||||
use std::collections::binary_heap::BinaryHeap;
|
||||
use std::cmp::Reverse;
|
||||
let len = s.len();
|
||||
|
||||
let mut parent = (0..len).collect::<Vec<usize>>();
|
||||
let mut rank = vec![1usize; len];
|
||||
|
||||
fn find(parent: &mut Vec<usize>, x: usize) -> usize {
|
||||
if x != parent[x] {
|
||||
parent[x] = find(parent, parent[x]);
|
||||
}
|
||||
return parent[x];
|
||||
}
|
||||
|
||||
fn union(parent: &mut Vec<usize>, rank: &mut Vec<usize>, x: usize, y: usize) {
|
||||
let root_x = find(parent, x);
|
||||
let root_y = find(parent, y);
|
||||
if root_x == root_y {
|
||||
return;
|
||||
}
|
||||
if rank[root_x] == rank[root_y] {
|
||||
parent[root_x] = root_y;
|
||||
rank[root_y] += 1;
|
||||
} else if rank[root_x] < rank[root_y] {
|
||||
parent[root_x] = parent[root_y];
|
||||
} else {
|
||||
parent[root_y] = parent[root_x];
|
||||
}
|
||||
}
|
||||
|
||||
for pair in pairs {
|
||||
union(&mut parent, &mut rank, pair[0] as usize, pair[1] as usize);
|
||||
}
|
||||
|
||||
let s = s.into_bytes();
|
||||
let mut map = HashMap::<usize, BinaryHeap<Reverse<u8>>>::new();
|
||||
for i in 0..len {
|
||||
let root = find(&mut parent, i);
|
||||
if map.contains_key(&root) {
|
||||
map.get_mut(&root).unwrap().push(Reverse(s[i]));
|
||||
} else {
|
||||
let mut min_heap = BinaryHeap::<Reverse<u8>>::new();
|
||||
min_heap.push(Reverse(s[i]));
|
||||
map.insert(root, min_heap);
|
||||
}
|
||||
}
|
||||
|
||||
let mut ret = String::with_capacity(len);
|
||||
for i in 0..len {
|
||||
let root = find(&mut parent, i);
|
||||
let c = map.get_mut(&root).unwrap().pop().unwrap().0;
|
||||
ret.push(c as char);
|
||||
}
|
||||
ret
|
||||
}
|
||||
|
||||
/// 1203.项目管理
|
||||
///
|
||||
/// [原题链接](https://leetcode-cn.com/problems/sort-items-by-groups-respecting-dependencies/)
|
||||
/// # 方法1 拓扑排序
|
||||
pub fn sort_items(n: i32, m: i32, group: Vec<i32>, before_items: Vec<Vec<i32>>) -> Vec<i32> {
|
||||
fn top_sort(deg: &mut Vec<usize>, graph: &mut Vec<Vec<usize>>, items: &mut Vec<usize>) -> Vec<usize> {
|
||||
let mut q = std::collections::VecDeque::<usize>::new();
|
||||
let n = items.len();
|
||||
for item in items {
|
||||
if deg[*item] == 0 {
|
||||
q.push_back(*item);
|
||||
}
|
||||
}
|
||||
let mut res = Vec::<usize>::new();
|
||||
while !q.is_empty() {
|
||||
let u = q.pop_front().unwrap();
|
||||
res.push(u);
|
||||
for &v in &graph[u] {
|
||||
deg[v] -= 1;
|
||||
if deg[v] == 0 {
|
||||
q.push_back(v);
|
||||
}
|
||||
}
|
||||
}
|
||||
if res.len() == n {
|
||||
res
|
||||
} else {
|
||||
Vec::new()
|
||||
}
|
||||
}
|
||||
let mut group_item = vec![Vec::<usize>::new(); (n + m) as usize];
|
||||
let mut group_graph = vec![Vec::<usize>::new(); (n + m) as usize];
|
||||
let mut item_graph = vec![Vec::<usize>::new(); n as usize];
|
||||
|
||||
let mut group_degree = vec![0usize; (n + m) as usize];
|
||||
let mut item_degree = vec![0usize; n as usize];
|
||||
|
||||
let mut id = (0..((n + m) as usize)).collect::<Vec<usize>>();
|
||||
let mut left_id = m as usize;
|
||||
let mut group = group.into_iter().map(|x| x as usize).collect::<Vec<usize>>();
|
||||
for i in 0..(n as usize) {
|
||||
if group[i] == -1i32 as usize {
|
||||
group[i] = left_id;
|
||||
left_id += 1;
|
||||
}
|
||||
group_item[group[i]].push(i);
|
||||
}
|
||||
|
||||
for i in 0..(n as usize) {
|
||||
let curr_group_id = group[i];
|
||||
for &item in &before_items[i] {
|
||||
let before_group_id = group[item as usize];
|
||||
if before_group_id == curr_group_id {
|
||||
item_degree[i] += 1;
|
||||
item_graph[item as usize].push(i);
|
||||
} else {
|
||||
group_degree[curr_group_id] += 1;
|
||||
group_graph[before_group_id].push(curr_group_id);
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
let group_top_sort = top_sort(&mut group_degree, &mut group_graph, &mut id);
|
||||
if group_top_sort.is_empty() {
|
||||
return Vec::new();
|
||||
}
|
||||
let mut ans = Vec::<i32>::new();
|
||||
|
||||
for curr_group_id in group_top_sort {
|
||||
//let size = group_item[curr_group_id].len();
|
||||
if group_item[curr_group_id].len() == 0 {
|
||||
continue;
|
||||
}
|
||||
let res = top_sort(&mut item_degree, &mut item_graph, &mut group_item[curr_group_id]);
|
||||
if res.is_empty() {
|
||||
return Vec::<i32>::new();
|
||||
}
|
||||
for item in res {
|
||||
ans.push(item as i32);
|
||||
}
|
||||
}
|
||||
ans
|
||||
}
|
||||
|
||||
/// 684.冗余连接
|
||||
///
|
||||
/// [原题链接](https://leetcode-cn.com/problems/redundant-connection/)
|
||||
///
|
||||
/// # 方法1 并查集
|
||||
pub fn find_redundant_connection(edges: Vec<Vec<i32>>) -> Vec<i32> {
|
||||
fn find(parent: &mut Vec<usize>, index: usize) -> usize {
|
||||
if parent[index] != index {
|
||||
parent[index] = find(parent, parent[index]);
|
||||
}
|
||||
parent[index]
|
||||
}
|
||||
fn union(parent: &mut Vec<usize>, index1: usize, index2: usize) {
|
||||
let idx1 = find(parent, index1);
|
||||
let idx2 = find(parent, index2);
|
||||
parent[idx1] = idx2;
|
||||
}
|
||||
|
||||
let nodes_count = edges.len();
|
||||
let mut parent = (0..nodes_count + 1).collect::<Vec<usize>>();
|
||||
for edge in edges {
|
||||
let (node1, node2) = (edge[0] as usize, edge[1] as usize);
|
||||
if find(&mut parent, node1) != find(&mut parent, node2) {
|
||||
union(&mut parent, node1, node2);
|
||||
} else {
|
||||
return edge;
|
||||
}
|
||||
}
|
||||
Vec::<i32>::new()
|
||||
}
|
||||
|
||||
/// 1018.可被5整除的二进制前缀
|
||||
///
|
||||
/// [原题链接](https://leetcode-cn.com/problems/binary-prefix-divisible-by-5/)
|
||||
pub fn prefixes_div_by5(a: Vec<i32>) -> Vec<bool> {
|
||||
let mut ret = Vec::<bool>::with_capacity(a.len());
|
||||
let mut s = 0;
|
||||
for n in a {
|
||||
s = ((s << 1) + n) % 5;
|
||||
ret.push(s == 0);
|
||||
}
|
||||
ret
|
||||
}
|
||||
|
||||
/// 947.移除最多的同行或同列石头
|
||||
///
|
||||
/// [原题链接](https://leetcode-cn.com/problems/most-stones-removed-with-same-row-or-column/)
|
||||
/// # 方法1 并查集
|
||||
/// 实现见源码
|
||||
/// # 方法2 dfs
|
||||
pub fn remove_stones(stones: Vec<Vec<i32>>) -> i32 {
|
||||
use std::collections::HashMap;
|
||||
let mut parent = HashMap::<usize, usize>::new();
|
||||
let mut count = 0usize;
|
||||
fn find(parent: &mut HashMap<usize, usize>, count: &mut usize, x: usize) -> usize {
|
||||
if !parent.contains_key(&x) {
|
||||
parent.insert(x, x);
|
||||
*count += 1;
|
||||
}
|
||||
if x != parent[&x] {
|
||||
let v = find(parent, count, parent[&x]);
|
||||
parent.insert(x, v);
|
||||
}
|
||||
parent[&x]
|
||||
}
|
||||
|
||||
for stone in &stones {
|
||||
let root_x = find(&mut parent, &mut count, !stone[0] as usize);
|
||||
let root_y = find(&mut parent, &mut count, stone[1] as usize);
|
||||
if root_x == root_y {
|
||||
continue;
|
||||
}
|
||||
parent.insert(root_x, root_y);
|
||||
count -= 1;
|
||||
}
|
||||
|
||||
(stones.len() - count) as i32
|
||||
}
|
||||
|
||||
/// 803.打砖块
|
||||
///
|
||||
/// [原题链接](https://leetcode-cn.com/problems/bricks-falling-when-hit/)
|
||||
/// # 方法1 并查集
|
||||
pub fn hit_bricks(grid: Vec<Vec<i32>>, hits: Vec<Vec<i32>>) -> Vec<i32> {
|
||||
const DIRECTIONS: [[i32; 2]; 4] = [[0, 1], [1, 0], [-1, 0], [0, -1]];
|
||||
let rows = grid.len();
|
||||
let cols = grid[0].len();
|
||||
let mut copy = grid.clone();
|
||||
for hit in &hits {
|
||||
copy[hit[0] as usize][hit[1] as usize] = 0;
|
||||
}
|
||||
let grid_len = rows * cols;
|
||||
|
||||
let mut parent = (0..(grid_len + 1)).collect::<Vec<usize>>();
|
||||
let mut size = vec![1usize; grid_len + 1];
|
||||
|
||||
fn in_area(x: usize, y: usize, rows: usize, cols: usize) -> bool {
|
||||
x < rows && y < cols
|
||||
}
|
||||
fn get_idx(x: usize, y: usize, cols: usize) -> usize {
|
||||
x * cols + y
|
||||
}
|
||||
fn find(parent: &mut Vec<usize>, x: usize) -> usize {
|
||||
if x != parent[x] {
|
||||
parent[x] = find(parent, parent[x]);
|
||||
}
|
||||
parent[x]
|
||||
}
|
||||
fn union(parent: &mut Vec<usize>, size: &mut Vec<usize>, x: usize, y: usize) {
|
||||
let root_x = find(parent, x);
|
||||
let root_y = find(parent, y);
|
||||
if root_x == root_y {
|
||||
return;
|
||||
}
|
||||
parent[root_x] = root_y;
|
||||
size[root_y] += size[root_x];
|
||||
}
|
||||
fn get_size(parent: &mut Vec<usize>, size: &mut Vec<usize>, x: usize) -> usize {
|
||||
return size[find(parent, x)];
|
||||
}
|
||||
|
||||
for j in 0..cols {
|
||||
if copy[0][j] == 1 {
|
||||
union(&mut parent, &mut size, j, grid_len);
|
||||
}
|
||||
}
|
||||
|
||||
for i in 1..rows {
|
||||
for j in 0..cols {
|
||||
if copy[i][j] == 1 {
|
||||
if copy[i - 1][j] == 1 {
|
||||
union(&mut parent, &mut size, get_idx(i - 1, j, cols), get_idx(i, j, cols));
|
||||
}
|
||||
if j > 0 && copy[i][j - 1] == 1 {
|
||||
union(&mut parent, &mut size, get_idx(i, j - 1, cols), get_idx(i, j, cols));
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
let mut res = vec![0i32; hits.len()];
|
||||
for i in (0..res.len()).rev() {
|
||||
let x = hits[i][0] as usize;
|
||||
let y = hits[i][1] as usize;
|
||||
if grid[x][y] == 0 {
|
||||
continue;
|
||||
}
|
||||
let origin = get_size(&mut parent, &mut size, grid_len);
|
||||
|
||||
if x == 0 {
|
||||
union(&mut parent, &mut size, y, grid_len);
|
||||
}
|
||||
|
||||
for direction in &DIRECTIONS {
|
||||
let new_x = (x as i32 + direction[0]) as usize;
|
||||
let new_y = (y as i32 + direction[1]) as usize;
|
||||
if in_area(new_x, new_y, rows, cols) && copy[new_x][new_y] == 1 {
|
||||
union(&mut parent, &mut size, get_idx(x, y, cols), get_idx(new_x, new_y, cols));
|
||||
}
|
||||
}
|
||||
|
||||
let current = get_size(&mut parent, &mut size, grid_len);
|
||||
res[i] = if current < origin + 1 {
|
||||
0
|
||||
} else {
|
||||
(current - origin - 1) as i32
|
||||
};
|
||||
copy[x][y] = 1;
|
||||
}
|
||||
res
|
||||
}
|
||||
|
||||
/// 1232.缀点成线
|
||||
///
|
||||
/// [原题链接](https://leetcode-cn.com/problems/check-if-it-is-a-straight-line/)
|
||||
|
|
@ -781,67 +413,6 @@ impl Solution {
|
|||
true
|
||||
}
|
||||
|
||||
/// 721.账户合并
|
||||
///
|
||||
/// [原题链接](https://leetcode-cn.com/problems/accounts-merge/)
|
||||
/// # 方法1 并查集
|
||||
pub fn accounts_merge(accounts: Vec<Vec<String>>) -> Vec<Vec<String>> {
|
||||
fn find(parent: &mut Vec<usize>, index: usize) -> usize {
|
||||
if parent[index] != index {
|
||||
parent[index] = find(parent, parent[index]);
|
||||
}
|
||||
parent[index]
|
||||
}
|
||||
fn union(parent: &mut Vec<usize>, index1: usize, index2: usize) {
|
||||
let idx1 = find(parent, index1);
|
||||
let idx2 = find(parent, index2);
|
||||
parent[idx2] = idx1;
|
||||
}
|
||||
use std::collections::HashMap;
|
||||
let mut email_to_idx = HashMap::<String, usize>::new();
|
||||
let mut email_to_name = HashMap::<String, String>::new();
|
||||
let mut emails_count = 0usize;
|
||||
for account in &accounts {
|
||||
let name = &account[0];
|
||||
for i in 1..account.len() {
|
||||
let email = &account[i];
|
||||
if !email_to_idx.contains_key(email) {
|
||||
email_to_idx.insert(email.clone(), emails_count);
|
||||
email_to_name.insert(email.clone(), name.clone());
|
||||
emails_count += 1;
|
||||
}
|
||||
}
|
||||
}
|
||||
let mut parent = (0..emails_count).collect::<Vec<usize>>();
|
||||
for account in &accounts {
|
||||
let first_email = &account[1];
|
||||
let first_idx = email_to_idx[first_email];
|
||||
for i in 2..account.len() {
|
||||
let next_email = &account[i];
|
||||
let next_idx = email_to_idx[next_email];
|
||||
union(&mut parent, first_idx, next_idx);
|
||||
}
|
||||
}
|
||||
let mut idx_to_emails = HashMap::<usize, Vec<String>>::new();
|
||||
for email in email_to_idx.keys() {
|
||||
let idx = find(&mut parent, email_to_idx[email]);
|
||||
if !idx_to_emails.contains_key(&idx) {
|
||||
idx_to_emails.insert(idx, Vec::<String>::new());
|
||||
}
|
||||
idx_to_emails.get_mut(&idx).unwrap().push(email.clone());
|
||||
}
|
||||
let mut merged = Vec::<Vec<String>>::new();
|
||||
for emails in idx_to_emails.values_mut() {
|
||||
emails.sort();
|
||||
let name = &email_to_name[&emails[0]];
|
||||
let mut account = Vec::<String>::with_capacity(1usize + emails.len());
|
||||
account.push(name.clone());
|
||||
account.extend(emails.clone());
|
||||
merged.push(account);
|
||||
}
|
||||
merged
|
||||
}
|
||||
|
||||
/// 1584.连接所有点的最小费用
|
||||
///
|
||||
/// [原题链接](https://leetcode-cn.com/problems/min-cost-to-connect-all-points/)
|
||||
|
|
@ -1211,26 +782,6 @@ impl Solution {
|
|||
ans
|
||||
}
|
||||
|
||||
/// 989.数组形式的整数加法
|
||||
///
|
||||
/// [原题链接](https://leetcode-cn.com/problems/add-to-array-form-of-integer/)
|
||||
pub fn add_to_array_form(mut a: Vec<i32>, mut k: i32) -> Vec<i32> {
|
||||
let mut carry = 0;
|
||||
for n in a.iter_mut().rev() {
|
||||
*n = *n + k % 10 + carry;
|
||||
carry = *n / 10;
|
||||
k /= 10;
|
||||
*n %= 10;
|
||||
}
|
||||
while k != 0 || carry != 0 {
|
||||
carry = k % 10 + carry;
|
||||
a.insert(0, carry % 10);
|
||||
k /= 10;
|
||||
carry /= 10;
|
||||
}
|
||||
a
|
||||
}
|
||||
|
||||
/// 1319.连通网络的操作次数
|
||||
///
|
||||
/// [原题链接](https://leetcode-cn.com/problems/number-of-operations-to-make-network-connected/)
|
||||
|
|
@ -1272,91 +823,6 @@ impl Solution {
|
|||
set_count as i32 - 1
|
||||
}
|
||||
|
||||
/// 674.最长连续递增序列
|
||||
///
|
||||
/// [原题链接](https://leetcode-cn.com/problems/longest-continuous-increasing-subsequence/)
|
||||
pub fn find_length_of_lcis(nums: Vec<i32>) -> i32 {
|
||||
let mut ans = 0;
|
||||
let mut start = 0;
|
||||
for i in 0..nums.len() {
|
||||
if i > 0 && nums[i] <= nums[i - 1] {
|
||||
start = i;
|
||||
}
|
||||
ans = ans.max(i - start + 1);
|
||||
}
|
||||
ans as i32
|
||||
}
|
||||
|
||||
/// 959.由斜杠划分区域
|
||||
///
|
||||
/// [原题链接](https://leetcode-cn.com/problems/regions-cut-by-slashes/)
|
||||
pub fn regions_by_slashes(grid: Vec<String>) -> i32 {
|
||||
fn find(parent: &mut Vec<usize>, x: usize) -> usize {
|
||||
if parent[x] == x {
|
||||
x
|
||||
} else {
|
||||
parent[x] = find(parent, parent[x]);
|
||||
parent[x]
|
||||
}
|
||||
}
|
||||
fn union(parent: &mut Vec<usize>, x: usize, y: usize) {
|
||||
let x_root = find(parent, x);
|
||||
let y_root = find(parent, y);
|
||||
parent[x_root] = y_root;
|
||||
}
|
||||
let n = grid.len();
|
||||
let mut parent = (0..(n * n * 4)).collect::<Vec<usize>>();
|
||||
for (i, s) in grid.into_iter().enumerate() {
|
||||
let s = s.into_bytes();
|
||||
for j in 0..n {
|
||||
let idx = i * n + j;
|
||||
if i < n - 1 {
|
||||
let bottom = idx + n;
|
||||
union(&mut parent, idx * 4 + 2, bottom * 4);
|
||||
}
|
||||
if j < n - 1 {
|
||||
let right = idx + 1;
|
||||
union(&mut parent, idx * 4 + 1, right * 4 + 3);
|
||||
}
|
||||
if s[j] == b'/' {
|
||||
union(&mut parent, idx * 4, idx * 4 + 3);
|
||||
union(&mut parent, idx * 4 + 1, idx * 4 + 2);
|
||||
} else if s[j] == b'\\' {
|
||||
union(&mut parent, idx * 4, idx * 4 + 1);
|
||||
union(&mut parent, idx * 4 + 2, idx * 4 + 3);
|
||||
} else {
|
||||
union(&mut parent, idx * 4, idx * 4 + 1);
|
||||
union(&mut parent, idx * 4 + 1, idx * 4 + 2);
|
||||
union(&mut parent, idx * 4 + 2, idx * 4 + 3);
|
||||
}
|
||||
}
|
||||
}
|
||||
let mut fathers = std::collections::HashSet::<usize>::new();
|
||||
for i in 0..(n * n * 4) {
|
||||
let fa = find(&mut parent, i);
|
||||
fathers.insert(fa);
|
||||
}
|
||||
fathers.len() as i32
|
||||
}
|
||||
|
||||
/// 1128.等价多米诺骨牌对的数量
|
||||
///
|
||||
/// [原题链接](https://leetcode-cn.com/problems/number-of-equivalent-domino-pairs/)
|
||||
pub fn num_equiv_domino_pairs(dominoes: Vec<Vec<i32>>) -> i32 {
|
||||
let mut m = std::collections::HashMap::<i32, i32>::new();
|
||||
let mut ret = 0;
|
||||
for d in dominoes {
|
||||
let key = if d[0] < d[1] {
|
||||
d[0] * 10 + d[1]
|
||||
} else {
|
||||
d[1] * 10 + d[0]
|
||||
};
|
||||
ret += m.get(&key).unwrap_or(&0);
|
||||
*m.entry(key).or_default() += 1;
|
||||
}
|
||||
ret
|
||||
}
|
||||
|
||||
/// 1579.保证图可完全遍历
|
||||
///
|
||||
/// [原题链接](https://leetcode-cn.com/problems/remove-max-number-of-edges-to-keep-graph-fully-traversable/)
|
||||
|
|
@ -1424,22 +890,6 @@ impl Solution {
|
|||
ans
|
||||
}
|
||||
|
||||
/// 724.寻找数组的中心索引
|
||||
///
|
||||
/// [原题链接](https://leetcode-cn.com/problems/find-pivot-index/)
|
||||
pub fn pivot_index(nums: Vec<i32>) -> i32 {
|
||||
let mut sum_right = nums.iter().sum::<i32>();
|
||||
let mut sum_left = 0;
|
||||
for i in 0..nums.len() {
|
||||
sum_right -= nums[i];
|
||||
if sum_left == sum_right {
|
||||
return i as i32;
|
||||
}
|
||||
sum_left += nums[i];
|
||||
}
|
||||
-1
|
||||
}
|
||||
|
||||
/// 面试题 01.08.零矩阵
|
||||
///
|
||||
/// [原题链接](https://leetcode-cn.com/problems/zero-matrix-lcci/)
|
||||
|
|
@ -1583,104 +1033,6 @@ impl Solution {
|
|||
}
|
||||
dist[m * n - 1]
|
||||
}*/
|
||||
|
||||
/// 778.水位上升的泳池中游泳
|
||||
///
|
||||
/// [原题链接](https://leetcode-cn.com/problems/swim-in-rising-water/)
|
||||
/// # 方法1 二分查找
|
||||
/// # 方法2 并查集
|
||||
/// # 方法3 Dijkstra 算法
|
||||
pub fn swim_in_water(grid: Vec<Vec<i32>>) -> i32 {
|
||||
const DIRS: [(i32, i32); 4] = [(-1, 0), (1, 0), (0, -1), (0, 1)];
|
||||
#[derive(PartialEq, Eq)]
|
||||
struct Item(usize, usize, i32);
|
||||
impl PartialOrd for Item {
|
||||
fn partial_cmp(&self, other: &Self) -> Option<std::cmp::Ordering> {
|
||||
other.2.partial_cmp(&self.2)
|
||||
}
|
||||
}
|
||||
impl Ord for Item {
|
||||
fn cmp(&self, other: &Self) -> std::cmp::Ordering {
|
||||
other.2.cmp(&self.2)
|
||||
}
|
||||
}
|
||||
let n = grid.len();
|
||||
let mut queue = std::collections::binary_heap::BinaryHeap::<Item>::new();
|
||||
queue.push(Item(0, 0, grid[0][0]));
|
||||
let mut dist = vec![vec![(n * n) as i32; n]; n];
|
||||
dist[0][0] = grid[0][0];
|
||||
let mut visited = vec![vec![false; n]; n];
|
||||
while !queue.is_empty() {
|
||||
let Item(x, y, _) = queue.pop().unwrap();
|
||||
if visited[x][y] { continue; }
|
||||
if x == n - 1 && y == n - 1 { return dist[n - 1][n - 1]; }
|
||||
visited[x][y] = true;
|
||||
for (dx, dy) in DIRS.iter() {
|
||||
let (nx, ny) = ((x as i32 + dx) as usize, (y as i32 + dy) as usize);
|
||||
if nx < n && ny < n && !visited[nx][ny] && grid[nx][ny].max(dist[x][y]) < dist[nx][ny] {
|
||||
dist[nx][ny] = grid[nx][ny].max(dist[x][y]);
|
||||
queue.push(Item(nx, ny, grid[nx][ny]));
|
||||
}
|
||||
}
|
||||
}
|
||||
-1
|
||||
}
|
||||
|
||||
/// 839.相似字符串组
|
||||
///
|
||||
/// [原题链接](https://leetcode-cn.com/problems/similar-string-groups/)
|
||||
/// # 方法1 并查集
|
||||
pub fn num_similar_groups(strs: Vec<String>) -> i32 {
|
||||
fn find(parent: &mut Vec<usize>, x: usize) -> usize {
|
||||
if parent[x] == x {
|
||||
x
|
||||
} else {
|
||||
parent[x] = find(parent, parent[x]);
|
||||
parent[x]
|
||||
}
|
||||
}
|
||||
fn check(a: &Vec<u8>, b: &Vec<u8>, len: usize) -> bool {
|
||||
let mut num = 0;
|
||||
for i in 0..len {
|
||||
if a[i] != b[i] {
|
||||
num += 1;
|
||||
if num > 2 { return false; }
|
||||
}
|
||||
}
|
||||
true
|
||||
}
|
||||
let (n, m) = (strs.len(), strs[0].len());
|
||||
let mut parent = (0..n).collect::<Vec<usize>>();
|
||||
let bytes_arr = strs.into_iter().map(|s| s.into_bytes()).collect::<Vec<Vec<u8>>>();
|
||||
for i in 0..n {
|
||||
for j in i + 1..n {
|
||||
let (fi, fj) = (find(&mut parent, i), find(&mut parent, j));
|
||||
if fi == fj { continue; }
|
||||
if check(&bytes_arr[i], &bytes_arr[j], m) {
|
||||
parent[fi] = fj;
|
||||
}
|
||||
}
|
||||
}
|
||||
parent.into_iter().enumerate().filter(|(i, n)| *i == *n).count() as i32
|
||||
}
|
||||
|
||||
/// 888.公平的糖果棒交换
|
||||
///
|
||||
/// [原题链接](https://leetcode-cn.com/problems/fair-candy-swap/)
|
||||
pub fn fair_candy_swap(a: Vec<i32>, b: Vec<i32>) -> Vec<i32> {
|
||||
use std::iter::FromIterator;
|
||||
let delta = (a.iter().sum::<i32>() - b.iter().sum::<i32>()) / 2;
|
||||
let set = std::collections::HashSet::<i32>::from_iter(a.into_iter());
|
||||
let mut ans = vec![];
|
||||
for y in b {
|
||||
let x = y + delta;
|
||||
if set.contains(&x) {
|
||||
ans = vec![x, y];
|
||||
break;
|
||||
}
|
||||
}
|
||||
ans
|
||||
}
|
||||
}
|
||||
|
||||
// 单元测试
|
||||
|
|
@ -1714,15 +1066,6 @@ mod tests {
|
|||
assert_eq!(i, 2);
|
||||
}
|
||||
|
||||
#[test]
|
||||
fn test_add_to_array_form() {
|
||||
let a = vec![1];
|
||||
let k = 9999;
|
||||
let b = Solution::add_to_array_form(a, k);
|
||||
//println!("{:?}", b);
|
||||
assert_eq!(b, vec![1, 0, 0, 0, 0]);
|
||||
}
|
||||
|
||||
#[test]
|
||||
fn test_find_critical_and_pseudo_critical_edges() {
|
||||
let n = 5;
|
||||
|
|
@ -1740,23 +1083,6 @@ mod tests {
|
|||
assert_eq!(ret, 20);
|
||||
}
|
||||
|
||||
#[test]
|
||||
fn test_hit_bricks() {
|
||||
let grid = vec![vec![1, 0, 0, 0], vec![1, 1, 1, 0]];
|
||||
let hits = vec![vec![1, 0]];
|
||||
let vec1 = Solution::hit_bricks(grid, hits);
|
||||
//println!("{:?}", vec1);
|
||||
assert_eq!(vec1, vec![2]);
|
||||
}
|
||||
|
||||
#[test]
|
||||
fn test_large_group_positions() {
|
||||
let s = "abcdddeeeeaabbbcd".to_string();
|
||||
let vec = Solution::large_group_positions(s);
|
||||
//println!("{:?}", vec);
|
||||
assert_eq!(vec, vec![vec![3, 5], vec![6, 9], vec![12, 14]]);
|
||||
}
|
||||
|
||||
#[test]
|
||||
fn test_find_numbers() {
|
||||
let i = vec![12, 345, 2, 6, 7896];
|
||||
|
|
@ -1764,28 +1090,4 @@ mod tests {
|
|||
//println!("{}", n);
|
||||
assert_eq!(n, 2);
|
||||
}
|
||||
|
||||
#[test]
|
||||
fn test_find_redundant_connection() {
|
||||
let edges = vec![vec![1, 2], vec![2, 3], vec![3, 4], vec![1, 4], vec![1, 5]];
|
||||
let redundant_connection = Solution::find_redundant_connection(edges);
|
||||
//println!("{:?}", redundant_connection);
|
||||
assert_eq!(redundant_connection, vec![1, 4]);
|
||||
}
|
||||
|
||||
#[test]
|
||||
fn test_prefixes_div_by5() {
|
||||
let a = vec![0, 1, 1, 1, 1, 1, 0, 1, 0];
|
||||
let by5 = Solution::prefixes_div_by5(a);
|
||||
//println!("{:?}", by5);
|
||||
assert_eq!(by5, vec![true, false, false, false, true, false, false, true, true]);
|
||||
}
|
||||
|
||||
#[test]
|
||||
fn test_remove_stones() {
|
||||
let stones = vec![vec![0, 0], vec![0, 1], vec![1, 0], vec![1, 2], vec![2, 1], vec![2, 2]];
|
||||
let i = Solution::remove_stones(stones);
|
||||
//println!("{}", i);
|
||||
assert_eq!(i, 5);
|
||||
}
|
||||
}
|
||||
Loading…
Reference in New Issue